בפוסט הקודם, הסברתי על איך מתקינים TFLite על רספברי פיי וגם הדגמנו בהדגמה פשוטה ונחמדה על סיווג תמונות. השתמשנו במודל מ-Kaggle שמזהה אובייקטים ויכול לזהות כמה אובייקטים מוגדרים מראש בתמונה או בפלט וידאו.
הבנת הצורך ובחירת המודל
לפעמים אנחנו צריכים מודל שיזהה דברים שייחודיים לנו. למשל, במקרה שלי, סל כביסה מלא. יש לי פרויקט שבמסגרתו מצלמה קטנה שולחת את התמונות של סל הכביסה אל רספברי פיי. במידה והסל מלא, הרספברי פיי שולח הודעה לילדים שצריך לרוקן את הסל. אם אני אשתמש במודל זיהוי אובייקטים מוכן, כלום לא יעבוד כיוון שסט האובייקטים לא כולל סל כביסה ריק או מלא. יש שם ״ציפור״, ״כלב״, ״חתול״ֿ, ״אדם״ ושאר חפצים יומיומיים. אבל סל כביסה מלא? לא. בגלל זה אני צריך משהו משלי.
יש לנו כמה סוגי מודלים. את מודל זיהוי האובייקטים הכרנו בפוסט הקודם. הוא מראה לנו שיש אובייקטים בתמונה ויכול גם לזהות עבורנו באיזה חלק בתמונה הם נמצאים. אבל במקרה הזה הצורך הוא מעט שונה: המצלמה קבועה ואנחנו צריכים מודל שיגיד לנו אם הסל שהיא מצלמת הוא מלא או ריק. זה נקרא סיווג תמונה או Image Classification. אני שולח תמונה כקלט והפלט הוא האם הסל מלא. מודלים כאלו מעט יותר קלים לאימון ולא נדרש המון כוח עיבוד או תמונות כדי להצליח לייצר מודל כזה.
השגת התמונות לאימון
על מנת שהמודל ״ילמד״, אנחנו צריכים לספק לו תמונות של הסיווגים. במקרה שלנו זה סל מלא וסל ריק. מומלץ מאד לצלם את התמונה עם הציוד שעוקב אחריה (למשל המצלמה של הרספברי פיי או כל מצלמה אחרת) אבל לא חובה. צילמתי עם הטלפון שלי כ-15 תמונות של הסל המלא וכמה של הסל הריק או ריק למחצה.

אימון המודל
עכשיו, אחרי שהשגתי את המידע, הגיע הזמן ליצור את המודל. יש אינספור שירותים שונים ליצירת מודלים. אבל השירות הידידותי והפשוט ביותר הוא teachablemachine. הוא שירות של גוגל מעולה ליצירת מודלים של סיווג תמונות, אינו דורש רישום וחינמי לגמרי.
נכנס אל האתר teachablemachine ונבחר ב-Image project. בחלון הבא פשוט ניצור את הסיווג הראשון שלנו: סל כביסה מלא. אפשר לאסוף את התמונות עם המצלמה המחוברת למחשב או להעלות אותם. במקרה הזה בחרתי להעלות.
נעלה גם לסיווג השני תמונות, במקרה שלי של סל כביסה ריק. אחרי שהעליתי ונתתי להם שמות. זה הזמן לאמן את המודל! אפשר לבחור בסוגים מתקדמים אבל לא חובה.
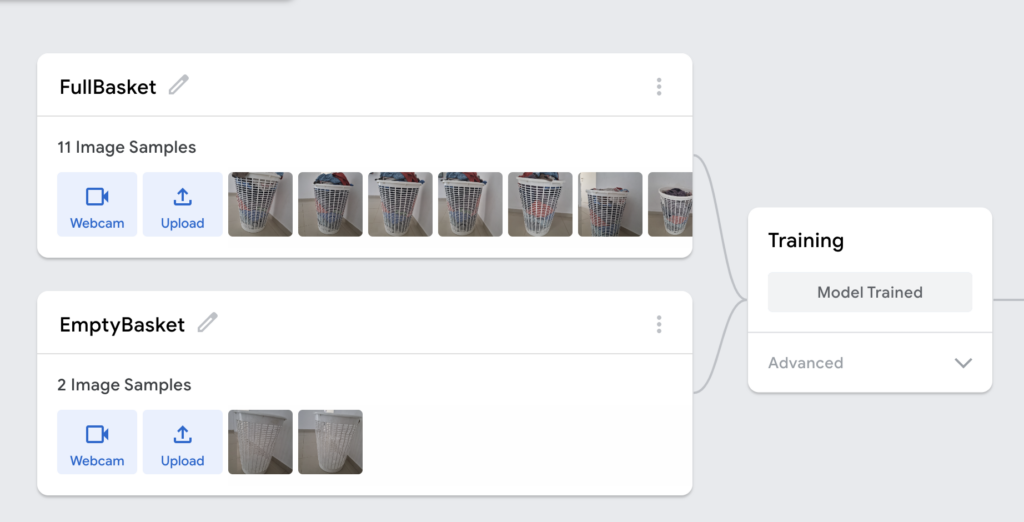
ו… זהו! מה חשבתם? שזה יהיה מתוחכם יותר? ????
עכשיו אפשר לבחון את המודל. ניתן להעלות אליו תמונה או להשתמש במצלמת הלפטופ.
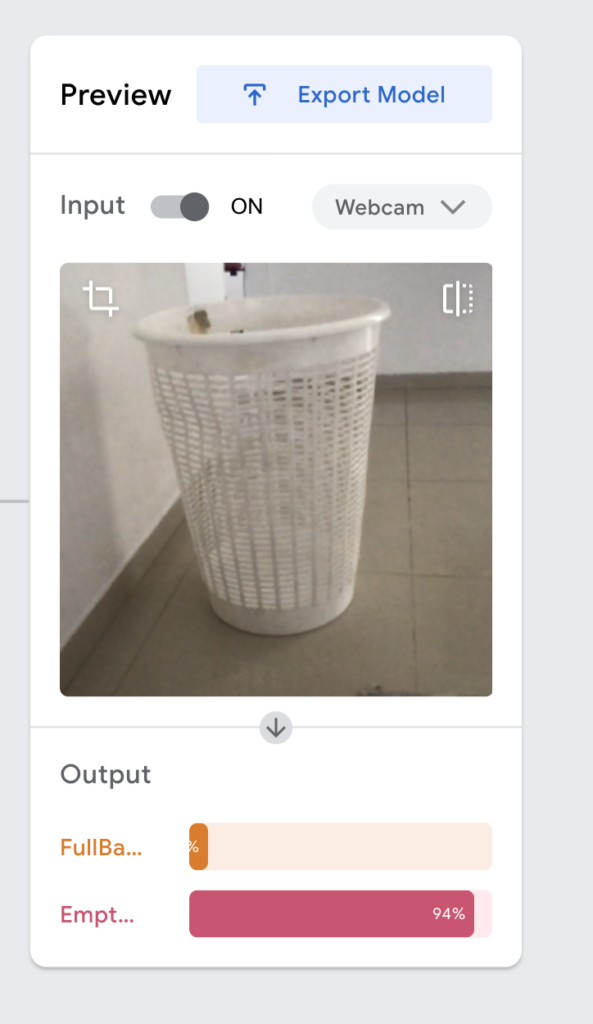
אנו נוכל לראות אם זה עובד או שיש בעיה. במקרה שיש בעיה פשוט מומלץ לצלם עוד תמונות ולראות שבאמת התמונות אם הן אותה רזולוציה ואותו דבר.
לייצא את המודל שלנו ל TFLite
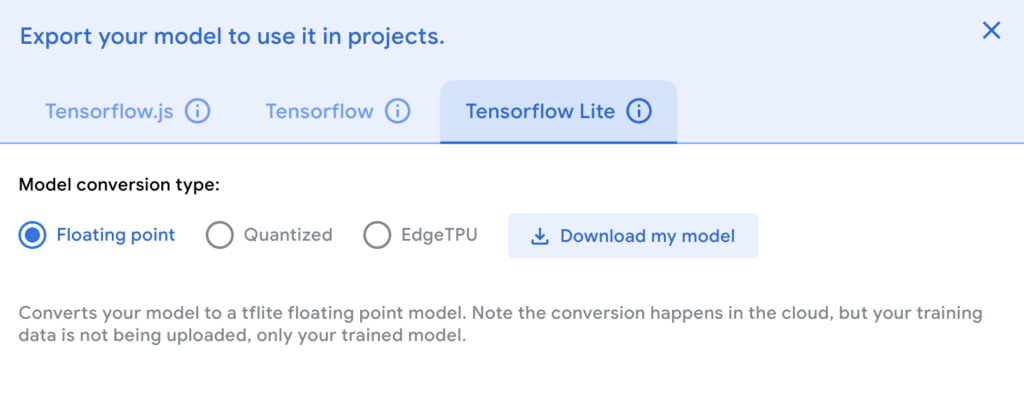
נלחץ על Export Model, נבחר בלשונית Tensorflow Lite (יש סיכוי שזה ישתנה לשם החדש – LiteRT) ונבחר ב-Floating point. יש לנו שני סוגים. הראשון הוא Floating point, שצורך יותר משאבים אבל יותר מדויק והשני הוא quantized שצורך פחות משאבים אבל פחות מדויק. כיוון שרספברי פיי זו מכונה חזקה יחסית, בחרתי ב-Floating point. נלחץ על ייצוא ונמתין בסבלנות עד שהמודל יסתיים לעבור הסבה וירד אל המחשב כקובץ zip.
אם נפתח את ה-zip נגלה שם שני קבצים – אחד הוא ה-labels והשני הוא בסיומת tflite – סיומת שאנחנו מכירים מהפוסט הקודם. עכשיו אפשר להעתיק את הקבצים אל הרספברי פיי שלנו (עם התוסף של VSCode זה ממש קל גם לערוך וגם להעתיק קבצים ואני ממליץ להשתמש בו) ולהשתמש בהם בקוד שלנו.
הנה הקוד שלי:
import tflite_runtime.interpreter as tflite
import numpy as np
from PIL import Image
# Custom class labels for the laundry basket detection
CUSTOM_LABELS = ["FullBasket", "EmptyBasket"]
# Load the TensorFlow Lite model and allocate tensors
model_path = "model_unquant.tflite" # Path to your TFLite model
interpreter = tflite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
# Get input and output tensor details
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Preprocess the image to the correct input format (resize to 224x224 and normalize for float32)
def preprocess_image(image_path):
img = Image.open(image_path).convert("RGB").resize((224, 224)) # Resizing to 224x224
input_data = np.expand_dims(np.array(img), axis=0).astype(np.float32)
# Normalize the image data for a float32 model (scale pixel values to [0, 1])
input_data = input_data / 255.0
return input_data
# Run inference on the preprocessed image
def run_inference(image_path):
input_data = preprocess_image(image_path)
# Set the input tensor for the interpreter and run inference
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
# Retrieve the output tensor (which is a 1x2 array of confidence scores)
output_data = interpreter.get_tensor(output_details[0]['index']) # Output confidence scores
return output_data
# Detect if the laundry basket is full or empty based on the confidence score
def detect_laundry_basket(image_path):
output_data = run_inference(image_path)
# Get the predicted class (the index of the highest confidence score)
predicted_class = np.argmax(output_data) # 0 for FullBasket, 1 for EmptyBasket
confidence = output_data[0][predicted_class] # The confidence score for the predicted class
# Print the detection result
print(f"{CUSTOM_LABELS[predicted_class]} detected with confidence {confidence:.2f}")
# Input image path
image_path = "laundry_basket.jpg" # Replace with the image file path to be tested
# Run laundry basket detection
detect_laundry_basket(image_path)
קוד כזה אפשר לייצר עם LLM בקלות (צ׳אטGPT במקרה שלי). פשוט הזנתי אליו שאילתה שכללה את ה-labels, איך יצרתי את המודל ואיזה סוג מודל זה ואת התוצאה. כדאי לשים לב שהקוד הזה שונה מהקוד שהדגמנו בפוסט הקודם כי מדובר במודל שלא מספק לנו זיהוי אובייקטים אלא סיווג תמונה.
יש גם ב-teachablemachine דוגמאות קוד של Tensorflow שאפשר להסב גם בקלות.
סיכום
עכשיו, אחרי שיש לי קוד שאליו אני מעביר תמונה ומקבל פידבק. אני יכול לתפור אליו פונקציונליות יותר טובה. מקור התמונה יכול להיות מצלמה של הרספברי פיי או מצלמה של ESP32 או כל מצלמה אחרת. גם אפשר לשלוח סמס או טלגרם לילדים או כל דבר אחר – כמו למשל קריאת API לנתב שיחתוך להם את האינטרנט. ברגע שמבינים איך AIoT עובד, אפשר באמת לחגוג. כמובן שלא חייבים לנטר סל כביסה. אפשר למשל חניה ריקה, קערת פירות ריקה או מלאה או כל דבר. אם אתם רוצים לצלול קצת יותר עמוק, הפוסט הנפלא הזה שמדגים זיהוי בננות מסביר את הבעייתיות של סיווג תמונה וראייה ממוחשבת באופן מהמם וכיפי במיוחד.
בפוסט הבא נכנס לעולם האמיתי עם תמונות אמיתיות ונלמד על איך מחברים את ESP32 לרספברי פיי ומחברים בין המודל שלמדנו להשתמש בו כעת למערכת גדולה הרבה יותר ופרויקט מלהיב.




7 תגובות
אבל מה קורה אם פשוט הזיזו את הסל מקום?
תשתמש בדמיון ???? תוסיף עוד class לרצפה ריקה.
יש אפשרות להגיד למודל לבחון כמה אובייקטים באותה תמונה?
התרחיש: מצלמה שתצלם את מגרש החניה הקטן מתחת לבית ותוכל להגיד לי מראש אם יש מקום אחד (לפחות) פנוי.
תודה
כן. אפשר להוסיף כמה class שרוצים. אני עשיתי עם סל כביסה מלא, חצי ריק וריק.
הי רן, מאד מעניין עושה חשק להטריל את הילדים 🙂
האם שמעת על המצלמה החדשה שפותחה בשיתוף סוני לרסברי פיי עם יכולות AI מובנות?
https://tech.eu/2024/09/30/sony-and-raspberry-pi-s-ai-camera-offers-a-new-era-of-economical-intelligent-vision-sensing-tech/
כן. אך לא ניסיתי עדיין 🙂 כן קניתי מתנת יום הולדת לעצמי את הצ׳יפ של ה-AI של Hailo ונראה כשזה יגיע איך זה עובד 🙂
רוצה לעשות מודול לפתיחה של תריס לפי זיהוי פנים של הילדים. מבחינת פרטיות מעדיף לא לעלות תמונות פנים של הילדים ל teachablemachine. אתה מכיר אפשרות לאמן את המודל בצורה לוקאלי?