אחד מכלי העזר השימושיים במערכת שאנו עושים לה סקיילינג היא אפאצ'י קפקא או בקיצור קפקא (כן, כמו הסופר הצ'כי הפופולרי). זה לא כלי שתצטרכו אותו במערכות קטנות, אתרים קטנים או אפליקציות קטנות. אנחנו משתמשים באפאצ'י קפקא כאשר אנו רוצים לעבוד במערכות גדולות שתומכות בהמוני משתמשים ועלולות להתקל בעומס.
מה זה סקיילינג? בואו נדמיין שניה שיש לנו API של רישום כלשהו. כמו למשל הצהרת בריאות קורונה לבית ספר. משתמש נכנס לאתר אינטרנט או אפיליקציה כלשהי ומשגר בקשת POST שיש בה את מספר הזהות של הילד, מספר הזהות של ההורה ואולי נתונים נוספים. השרת מקבל את הבקשה, שולח אותה לשירות של רישום שמעדכן את בית הספר. הנה מימוש מאוד נאיבי:
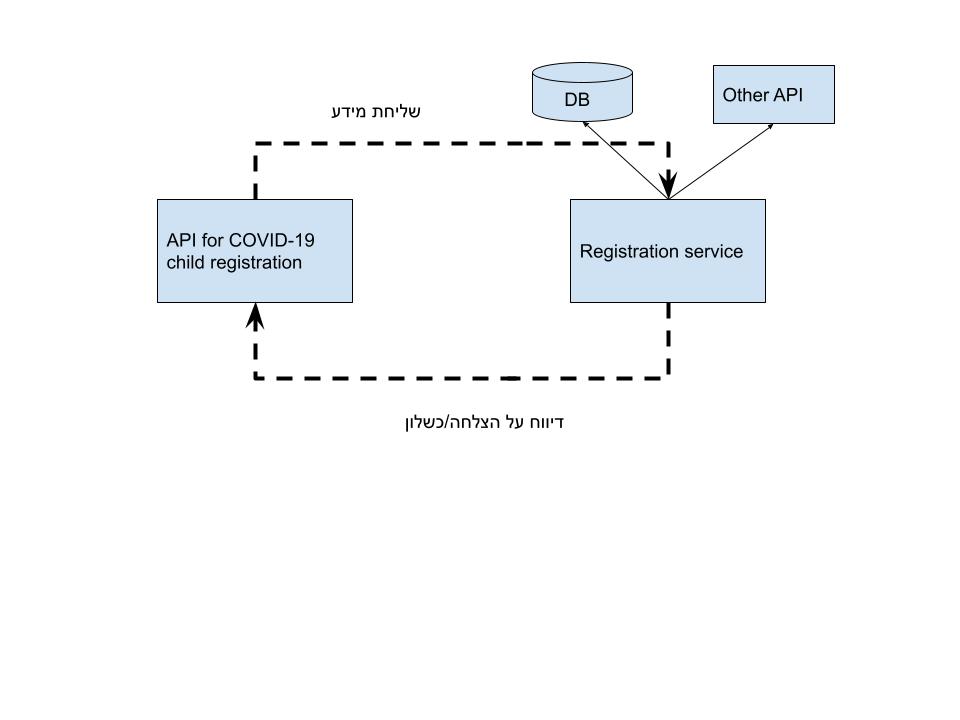
מה הבעיה עם המימוש הזה? הכל טוב ויפה אם יש לנו 1000 בקשות לשניה. אבל מה קורה אם יש לנו יותר, למשל אם כל הורי ישראל בשעה מסוימת מנסים לדווח? מה קורה אז? ומה קורה אם בנוסף לכל יש לנו מימוש קצת פחות נאיבי שבו אנו צריכים לדווח גם לשירות לוגינג או שירותים אחרים?
בדיוק בשביל זה יש לנו שירותי queue (הוגים כ"קיו"). יש כל מיני שירותים כאלו כמו RabbitMQ למשל או אם אתם משתמשי אמזון אז Amazon simple queue service (שזה Amazon SQS) אבל אני רוצה לדבר על אפאצ'י קפקא. באנגלית Apache Kafka. שירות קוד פתוח שכתוב בסקאלה שעוזר לנו לטפל בדיוק בדברים כאלו ובלא הרבה מאמץ. ויותר מזה, הוא עוזר לנו לשלוח את המידע למיקרו סרביסים רבים ולנהל את התור.
בגדול, מימוש נאיבי של תור – ולא משנה איך מממשים את התור הזה ובאיזה דיזיין הוא, נראה ככה.
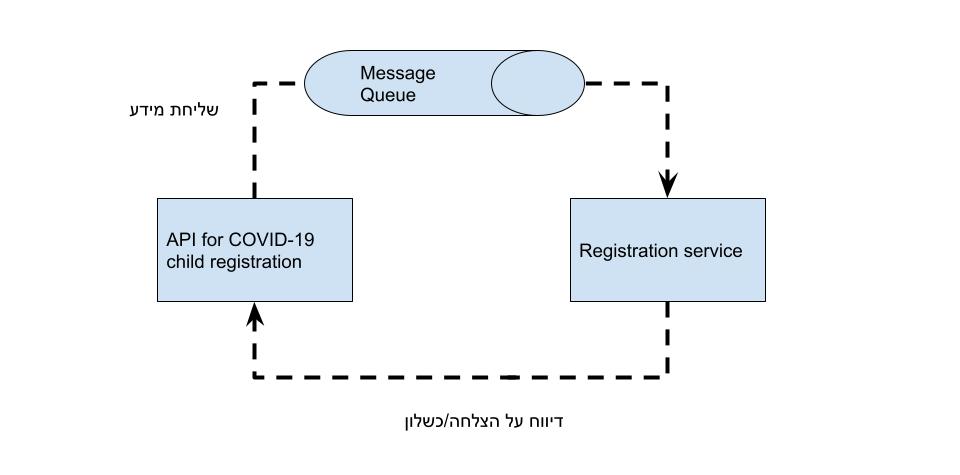
ה-API שולח את הבקשות לתור ומשם הן מגיעות לשירות לפי הסדר. השירות של הרישום קרס כי הוא לא עומד בעומס? המשתמש יחכה אולי למענה (האפליקציה תוכל לנהל את זה ואולי גם להגיב לו בהודעה שיש עומס זמני, או לתת אישור כמו שהן אמורות לעשות) או שבמקרה הזה לפתוח עוד instance, אבל עד אז השירות לא יקרוס ויוכל להמשיך לקבל בקשות והבקשות לא ילכו לאיבוד. כלומר זה ינוהל הרבה יותר טוב.
קפקא הוא גם מערכת שמטפלת באירועים אבל כזו שעובדת במודל מעט שונה של publishers\subscribers או pub\sub מה זאת אומרת? יש לנו את Kafka. שאליו אפשר לרשום הודעות או להאזין להודעות. כשיכולים להיות כמה מאזינים בהתאם להודעות.
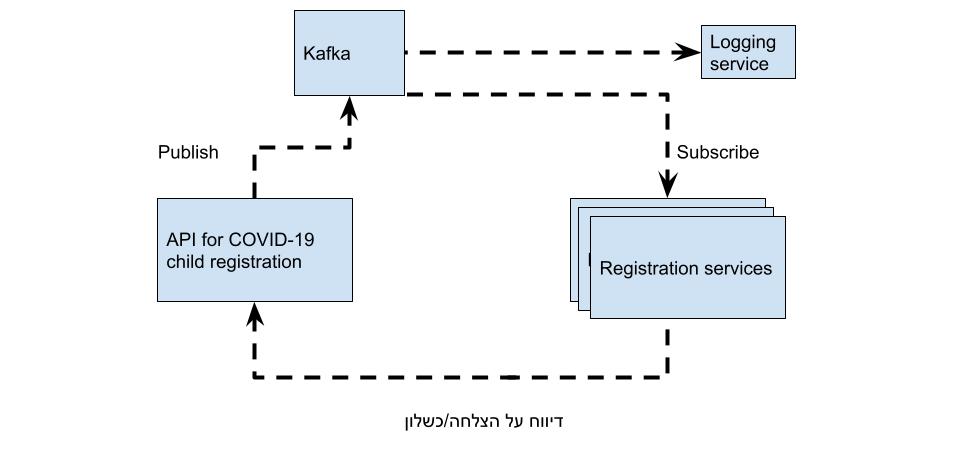
ההודעה בקפקא לא נמחקת מייד כשמישהו צורך אותה, היא נשארת בזכרון למשך זמן מוגדר ואז אם אחד ה-services נופל וחוזר אחרי כמה דקות הוא יכול לעבד את ההודעה. אבל מה שקורה שאין "תקיעות".
מה הקיבולת של kafka? תלוי במכונה שהוא נמצא עליו. אפשר ליצור Kafka Cluster שיכול לקבל מיליוני בקשות בשניה בלי שום בעיה וגם לבנות כמה פייפליינים (בקפקא הם נקראים ברוקרים) לצרכים שונים כדי לא לבזבז משאבים. מה שחשוב הוא שגם עם מכונה אחת שמריצה קפקא, אפשר להגיע להישגים מאוד יפים ולמנוע את המצב המביש של קריסות כשיש פיקים.
איך קפקא עובד?
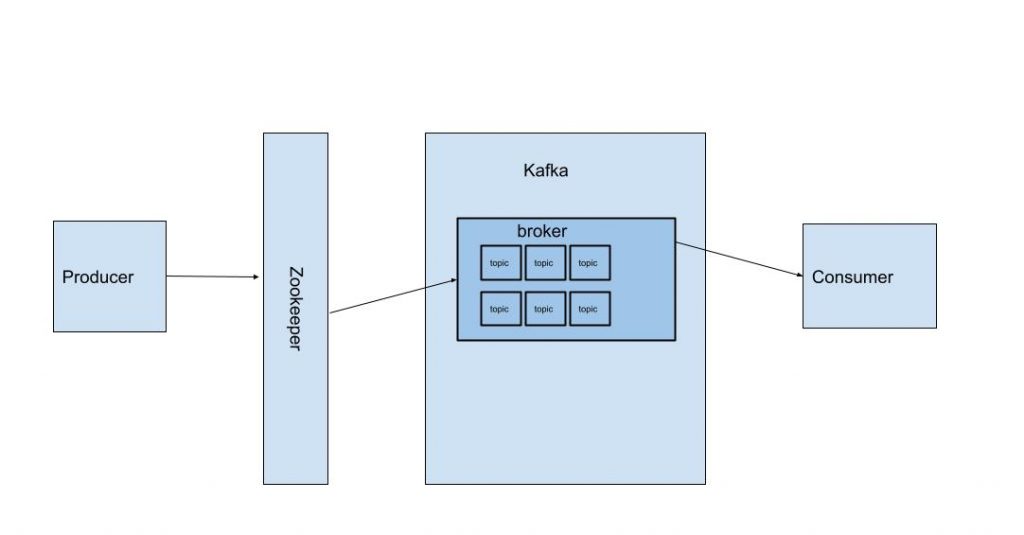
בגדול יש כמה מונחים שאנו צריכים להכיר:
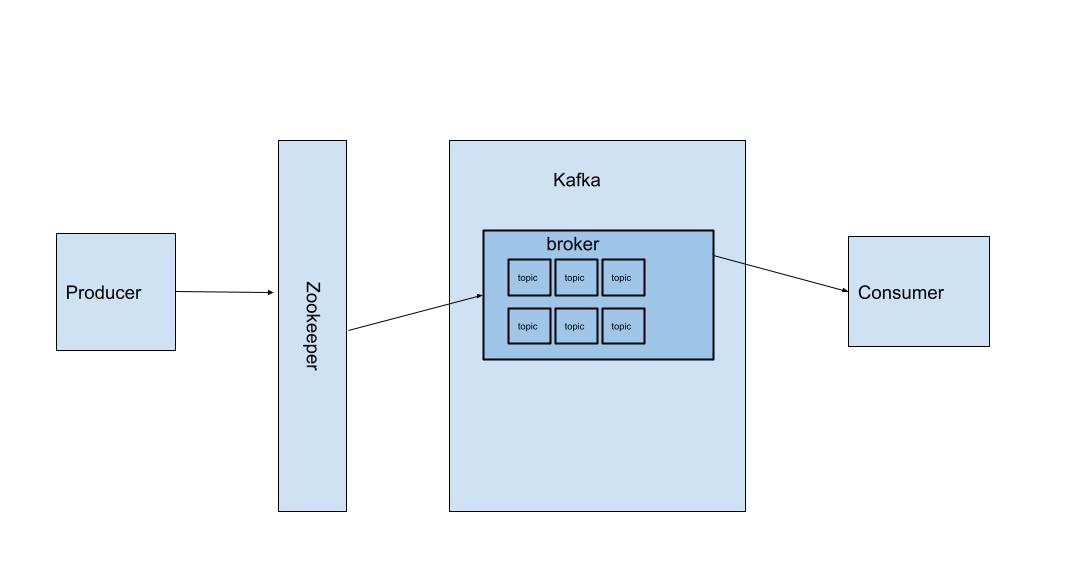
ZooKeeper – השכבה שלפני ה-Kafka שמחלקת את העומס בין הברוקרים לפי טיב ההודעות שה-producers שולח.
ברוקר – בעצם ה"צינור" הרלוונטי שאליו ההודעה נשלחת. במערכת מורכבת יש כמה צינורות כאלו. אחד למשל לדיווחי בריאות, השני לדיווחי תקלות ולוגינג, השלישי לדיווחים של אפליקציה אחרת המיועדת לרופאים. זה מאפשר לי לקבל כמה סוגי הודעות ולנתב אותן כי consumers יכולים להאזין לברוקרים שונים. במקרה הזה יש לי ברוקר אחד.
נושאים (שזה topics) – בכל ברוקר יש כמה נושאים. כי ברוקר הרי יכול לטפל בכמה סוגי הודעות.
מה שחשוב הוא כאשר מתקדמים לפיתוח יותר מעניין הוא להכיר את הכלים האלו. גם אם לא תממשו לעולם קפקא בפרודקשן בעצמכם, אם מישהו ביקש מכם להאזין לקפקא, אז אתם יודעים איך זה עובד. אבל אם להכיר אנו מכירים, מה עם לממש קפקא פשוט כדי לראות איך זה עובד בחי?
אפשר להרים קפקא בקלות על כל מכונה, בענן או לא בענן. אני אשתמש במכונת לינוקס שנמצאת אצלי (יותר נכון, מכונת רספברי פיי שנמצאות בדיוק בשביל הצורך הזה). ההתקנה של קפקא היא ממש פשוטה.
הורדה
נכנסים לאתר של Apache Kafka ומורידים ��ת הגרסה האחרונה. אפשר עם wget:
wget https://apache.mivzakim.net/kafka/2.8.0/kafka_2.13-2.8.0.tgzשימו לב שזו הגרסה העדכנית לשעת כתיבת המאמר, יש מצב שהגרסה האחרונה תשתנה. אז פשוט להכניס את הכתובת של הקובץ האחרון. נפתח את הקובץ עם tar zxf ונכנס לתיקיה.
tar -zxf kafka_2.13-2.8.0.tgz
cd kafka_2.13-2.8.0/הפעלת Zookeeper
הפעלת zookeeper נעשית באופן פשוט ממש:
bin/zookeeper-server-start.sh config/zookeeper.propertiesאחרי ההפעלה נפתח בטרמינל עוד טאב כדי להפעיל ברוקר.
הפעלת ברוקר
על מנת להפעיל ברוקר, אנו צריכים קובץ קונפיגורציה. יש אחד שנמצא כבר בקפקא. כנס לתיקיה שבה kafka נמצא, במקרה שלי עם:
cd kafka_2.13-2.8.0/ניתן לבחון אותו באמצעות:
nano config/server.propertiesסקירה שלו תיקח מאמר שלם, מה שחשוב מבחינתו הוא ה-id שלו. במקרה הזה נשנה אותו ל-1 – זה ה-id של הברוקר שלנו. נחפש את ההגדרה של broker.id ונשנה אותה ל-1.
גם נוכל לשנות את הכתובת של קובץ הלוג. למשל ל-/tmp/kafka-logs-1.
גם ההאזנה היא מאוד חשובה, אנו נוסיף את ההגדרה.
listeners = PLAINTEXT://:9092
אחרי שיש לנו את ההגדרה של ההאזנה ונזכור שהפורט הוא 9092.
מה שעוד חשוב להוסיף הוא את כתובת ה-IP שלכם כדי שיהיה אפשר להתחבר מרחוק למכונה.
advertised.listeners=PLAINTEXT://192.168.2.204:9092
אלו ההגדרות שחשוב שיהיה בקובץ הקונפיגורציה, שימו לב שכתובת ה-IP של המכונה צריכה להיות כתובת ה-IP של הרספברי פיי.
broker.id=1
listeners = PLAINTEXT://:9092
log.dirs=/tmp/kafka-logs-1
advertised.listeners=PLAINTEXT://192.168.2.204:9092נפעיל את הברוקר באמצעות:
bin/kafka-server-start.sh config/server.propertiesאני יכול להפעיל כמה ברוקרים שבא לי, כל אחד עם property משלו.
אז עכשיו יש לנו שני טאבים. אחד פתוח על ברוקר והשני על ה-zookeepers. יש לנו קפקא שעובד! בואו ונבדוק במהירות איך זה עובד.
יצירת טופיק
ראשית חייבים ליצור טופיק כך יוצרים אותו:
bin/kafka-topics.sh --create --topic demo-topic --bootstrap-server localhost:9092מאוד פשוט להבין איך בדיוק יצרתי אותו. שימו לב לפורט 9092 שהוא הפורט של הברוקר הראשון. אני יכול ליצור איזה טופיק שבא לי.
ליצור הודעות לטופיקים מה-CLI המקומי ולקרוא אותם
אנו יכולים ליצור הודעות (גם טופיקים) עם ספריות בהתאם לשפה שאנו משתמשים בה, כמו Node.js למשל. אבל אפשר גם דרך הטרמינל, רק כדי לבדוק שהכל עובד ומנגן כמו שצריך. כדי ליצור הודעה אנו נשתמש בסקריפט שנמצא ב-bin באופן הזה:
bin/kafka-console-producer.sh --topic demo-topic --bootstrap-server localhost:9092ייפתח לנו מקום שבו אנו יכולים להקליד. שימו לב שאם אתם בוחרים טופיק אחר, צריך לשנות את שמו אחרי הפלאג topic. אחרי שנקליד כמה שורות. אפשר ללחוץ על קונטרול C.

כדי לקרוא את ההודעה, כל מה שאנו צריכים לעשות זה להאזין לטופיק:
bin/kafka-console-consumer.sh --topic demo-topic --from-beginning --bootstrap-server localhost:9092ואנו נראה את כל ההודעות. איזה יופי! קפקא משלנו שעובד out of the box!
שימוש בספרית kafkajs
טוב, זה נחמד לוקלית. מה עם להתחבר לקפקא עם סקריפט של Node.js? טוב, זה די קל ונעים עם ספרית Node.js שנקראת kafka.js.
אנו ניצור פרויקט Node.js קטן ונתקין את kafkajs עם npm init && npm i kafkajs. נשמור את הקובץ הזה כ-index.js
const { Kafka } = require('kafkajs');
// the client ID lets Kafka know who's producing the messages
const clientId = 'my-app';
// Insert your own IP
const brokers = ['192.168.2.204:9092'];
// this is the topic name, should be matched with broker
const topic = 'demo-topic';
const kafka = new Kafka({ clientId, brokers });
const producer = kafka.producer();
const produce = async () => {
await producer.connect();
let i = 0;
setInterval(async () => {
try {
await producer.send({
topic,
messages: [
{
key: String(i),
value: `This is message ${i}`,
},
],
});
console.log('Produce: ', i);
i++;
} catch (err) {
console.error(`could not write message ${err}`);
}
}, 1000);
};
produce();
מה שהסקריפט הזה עושה הוא לשלוח הודעה, כ-producer לקפקא שלנו שיושב ברספברי פיי. כל שניה. אם תסתכלו על המכונה ברספברי, תוכלו לראות את ההודעות נשלחות בקצב לתוך הברוקר.
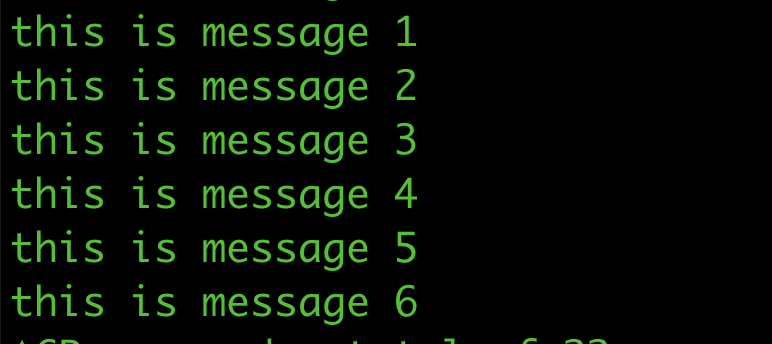
אפשר כמובן גם לבצע consume מאוד בקלות. נפתח פרויקט נוסף, אפילו על מכונה שלישית אם אתם רוצים, גם פה נתקין את kafkajs עם npm init && npm i kafkajs. נשמור את הקובץ הזה כ-index.js ונכניס לתוכו את הקוד שמבצע consume:
const { Kafka } = require('kafkajs');
// the client ID lets Kafka know who's producing the messages
const clientId = 'my-app';
// Insert your own IP
const brokers = ['192.168.2.204:9092'];
// this is the topic name, should be matched with broker
const topic = 'demo-topic';
const kafka = new Kafka({ clientId, brokers });
const consumer = kafka.consumer({ groupId: clientId });
const consume = async () => {
// first, we wait for the client to connect and subscribe to the given topic
await consumer.connect();
await consumer.subscribe({ topic });
await consumer.run({
// this function is called every time the consumer gets a new message
eachMessage: ({ message }) => {
// here, we just log the message to the standard output
console.log(`received message: ${message.value}`);
},
});
};
consume();
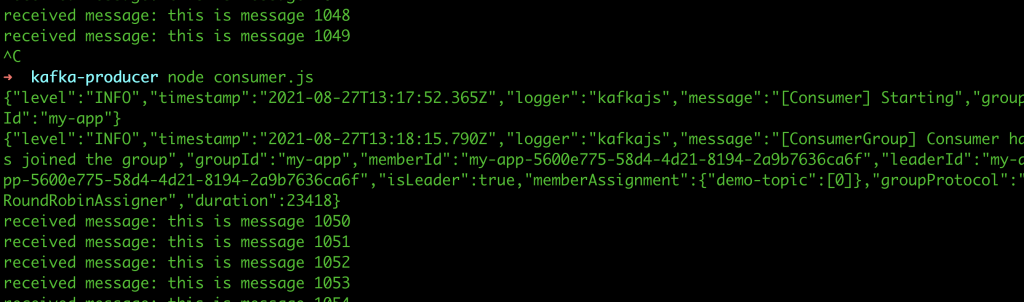
אנו נוכל לראות את ההודעות שלנו שרצות ממש בזמן אמת – גם על הרספברי פיי וגם כמובן בקליינט. ואם אני אריץ ��ליינט נוסף אני גם אראה את ההודעות האלו. אפשר לשלוח גם אובייקטים של JSON כמובן, אחרי שמשנים אותם לטקסט. הגודל של ההודעות מוגבל למגהבייט אחד.
עכשיו, שימו לב לגדולה של קפקא. אם תריצו את ה-consumer של ה-Node.js ותפילו אותו עם ctrl +c, נניח שיש עליו עודף משימות והוא קרס. עכשיו תרימו אותו חזרה – תראו שהוא חוזר לעבוד מאותה נקודה בדיוק. כלומר שום דבר לא אבד.
מה זה אומר? שאם נניח מיליון הורים שולחים הצהרת בריאות באותה שניה בדיוק (ב-7:59), קפקא בהחלט יכול לקבל את ההודעות האלו ולשלוח אותם ל-service כשהוא יכול לקבל אותן. וככה עובדים בסקייל בלי משאבים משוגעים של שרתים ל-service עצמו שלא יכול להתמודד עם ספייק של מיליון בקשות בשניה. הרי העיבוד והמשלוח יכולים להתקיים גם דקה אחר כך.
לסיכום
הראיתי איך בונים בבית סביבה של קפקא על רספברי פיי או כל מכונה אחרת. אין כל בעיה להריץ כמובן קפקא על המכונה הלוקלית, אבל עם מכונה קטנה כזו אפשר גם לעבוד יחד עם מפתחים אחרים או לנצח את הכוח של קפקא גם לדברים אחרים כמו IoT. יש המון מה ללמוד על קפקא, תלוי כמה רוצים להעמיק או להכנס אליו. זה נושא מאוד מעניין שקצת פחות רלוונטי למפתחים רגילים אבל בהחלט רלוונטי למי שמתעניין בסקייל גבוה.




6 תגובות
מדהים איך אתה מפשט פתרון לscale גבוה בכמה צעדים פשוטים בלי להמציא את הגלגל ובלי לעשות תהליכי פיתוח ארוכים. שאפו ענק (שירה שטיינבוך ביקשה למסור..) כמובן שהדבר עשוי להביא לא מעט אתגרים לחיבור ללוגיקה העסקית כמו למשל איך "להחזיר" תשובה למי ששלח את הבקשה. אשמח לתקציר על זה. תודה!
תודה רבה על המאמר! מאוד ברור ומלמד.
האם תוכל להרחיב על ההבדל בין קפקא לבין RabbitMQ?
מאוד מעניין ומעשיר
זה TIBCO. בזמנו עבדתי על מערכת של חברת ביטוח גדולה בחו"ל. תהליכים עבדו לאט. פרקנו אותן למיקרו תהליכים והקמנו מנועים שכל אחד מהם מטפל במיקרו תהליך כזה ומעביר Message לתור הבא. ככה יכולנו להפעיל כמה מנועים שרצינו על כל תור ולהשיג ביצועים של פי 10.
תודה רבה על הסבר ממצה וברור!
חסרה פקודת הבנייה של הפרוייקט.
לפני פתיחת ה bin/zookeeper-server-start.sh
צריך להרכיב את התוכנה [עם גריידל או בכל צורת בנייה של JAVA]