
אחת המגבלות הקשות של GPT היא שהוא לא יודע מה התרחש אחרי שהוא התאמן בספטמבר 2021. כמו כן, הוא לא יכול לדעת דברים מסוימים שלא מפורסמים. למשל, אם אני אשאל אותו על דוקומנטציה מסוימת שנמצאת רק באינטראנט של החברה – הוא לא ידע מה אני רוצה ממנו. אם אני אשאל אותו על קוד מסוים שהוא לא התאמן עליו, הוא לא ידע מה אני רוצה ממנו.
אני אמחיש באמצעות דוגמה פשוטה – שאלתי את GPT מתי יצרתי את הפול ריקווסט הראשון שלי בחברת סייברארק. ל-GPT הקלאסי אין מושג מה אני רוצה ממנו. המידע הזה לא הופיע ב-2021.
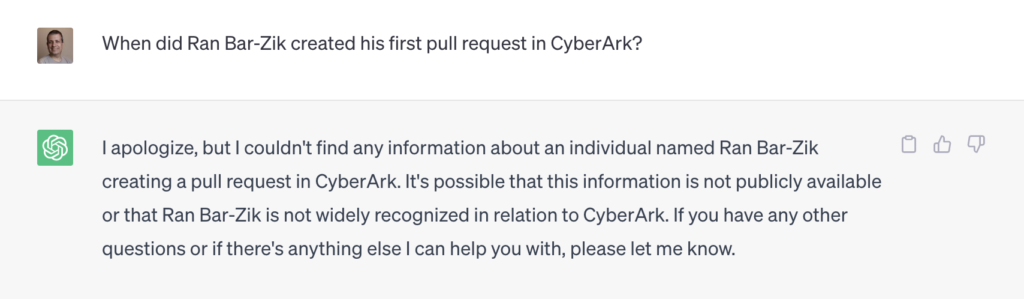
אבל המידע הזה כן הופיע אחרי 2021. באוגוסט 2022 התחלתי לעבוד בסייברארק ופרסמתי בנובמבר 2022 את הפוסט במדיום שבו אני מספר איך ביום הראשון עשיתי פול ריקווסט.
כמובן של-GPT לא יהיה מושג מזה. כי נובמבר 2022 התרחש אחרי 2021, הזמן שבו GPT התאמן.
כאמור, זו דוגמה בלבד – כי יכול להיות לנו למשל חומר שלא זמין ברשת – דוקומנטציה של מוצרים, קוד פרטי שלנו, טקסט שמופיע מאחורי חומת תשלום וכו׳ וכו׳. איך אני יכול לסרוק אותו.
יש תוכנה הנקראת llama index. התוכנה הזו, הזמינה כחבילה בפייתון וגם ב-Node.js, מאפשרת לנו לנתח מסמך אחד או יותר, במגוון פורמטים, ליצור מזה אינדקס שאפשר לתת כקונטקסט ל-GPT. כלומר לתת לו את הידע הזה ואז לשאול אותו שאלות שונות והוא ידע לענות גם דברים המופיעים במידע הזה, גם אם הוא לא התאמן עליו.
זה נשמע קצת אמורפי אז במקרה שלנו – אני יכול לתת ל-GPT את המאמר שלי במדיום ואז, אם אשאל אותו את אותה שאלה, הוא ידע לענות ש:
Ran Bar-Zik created his first pull request in CyberArk on August 2022, his first day at the company.
וזה? זה שימושי במיוחד. אפשר לתת מידע רב ל-GPT ולשאול אותו על בסיס המידע הזה. לא רק מאמר שכתבתי במדיום אלא מידע רב ונוסף – דוקומנטציה, מידע פנימי ואפילו קוד.
אז איך עושים את זה? אני אדגים בפייתון.
קביעת גרסת פייתון במחשב המקומי
ראשית, אני אקפיד שגרסת הפייתון שלי תהיה עדכנית. למשל 3.11.2. שימו לב שזה שלב קריטי. איך אני קובע את גרסת הפייתון שלי? למשל עם pyenv:
brew update && brew upgrade pyenv
pyenv install 3.11.2
pyenv global 3.11.2עם פואטרי אני אצור פרויקט באמצעות
poetry new context-demoעכשיו יש לי פרוייקט פייתוני מוכן. אצור קובץ main.py בתיקיה הראשית ותיקיה נוספת תחת התיקיה הראשית בשם data. לשם אני יכול לזרוק את כל קבצי הטקסט שאני רוצה ש GPT יוכל לקרוא. במקרה שלנו, פשוט שמרתי קובץ של המאמר במדיום כקובץ txt. זה יכול להיות ליטרלי כל דבר וכמובן כמה קבצים.
הכנסת המידע לתיקית data
אנו נכניס קבצי txt לתיקית data. במקרה שלי, העתקתי את המאמר ממדיום לקובץ טקסט והכנסתי אותו עם שם כלשהו לתיקיה. השמות לא חשובים ויכולים להיות כמה קבצים.
התקנת llama index
השלב הבא הוא להתקין את llama_index ואת dotenv. למה llama_index (חה!) כי אנחנו משתמשים בו לבנות את האינדקס. למה dotenv? כי אני לא מכניס מפתח API לקוד שלי כמו חיה.
poetry add llama-index python-dotenvעכשיו אנחנו מוכנים.
מפתח ה-API
ראשית נכנס לopenai כדי להשיג את המפתחות שלנו. אני מניח שיש לכם שם חשבון, הכנסו לחשבון ואז לכתובת https://platform.openai.com/account/api-keys וצרו מפתח. את המפתח תעתיקו.
אנחנו ניצור קובץ בתיקיה הראשית של הפרויקט בשם env. (שימו לב לנקודה בתחילת שם הקובץ) ונכניס לשם את הטקסט:
OPENAI_API_KEY=המפתח_שלכםבמקום ״המפתח_שלכם״ הכניסו את המפתח שקיבלתם מ-openAI ושימרו את הקובץ.
main.py
צרו קובץ בשם main.py והכניסו אליו את הקוד הזה. קודם כל אתן את הקוד המלא ואז נסביר עליו מעט:
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
import os
from dotenv import load_dotenv
load_dotenv()
class AddingDataToGPT:
def __init__(self):
self.index = None
self.persist_dir = "./storage"
self.data_dir = "./data"
if os.path.exists(self.persist_dir):
self.read_from_storage()
else:
self.build_storage()
query_engine = self.index.as_query_engine()
response = query_engine.query("When did Ran Bar-Zik created his first pull request in CyberArk?")
print(response)
def build_storage(self):
documents = SimpleDirectoryReader(self.data_dir).load_data()
self.index = GPTVectorStoreIndex.from_documents(documents)
self.index.storage_context.persist()
def read_from_storage(self):
storage_context = StorageContext.from_defaults(persist_dir=self.persist_dir)
self.index = load_index_from_storage(storage_context)
adding_data = AddingDataToGPT()
מה הקוד של main.py עושה
ראשית אני מבצע את ה-imports כמו שצריך וכן טוען את משתנה הסביבה OPENAI_API_KEY שדרוש על מנת לתשאל את Chat GPT.
בקלאס הנחמד הזה אני בודק אם יש לי תיקיה בשם storage.
במידה ולא, אני קורא ל-build_storage שקוראת את תיקית data ומנתחת אותה, מכניסה את הפלט לזכרון אבל גם לתיקיה בשם storage.
במידה וכן יש תיקיה בשם storage, אני קורא אותה ומכניס את הפלט לזכרון.
ברגע ש index קיים בזכרון, אני משגר קריאה עם השאלה. במקרה הזה – שאלה שיש אותה בקונטקסט שעכשיו יש לChat GPT – המאמר שכתבתי. התשובה שתהיה היא:
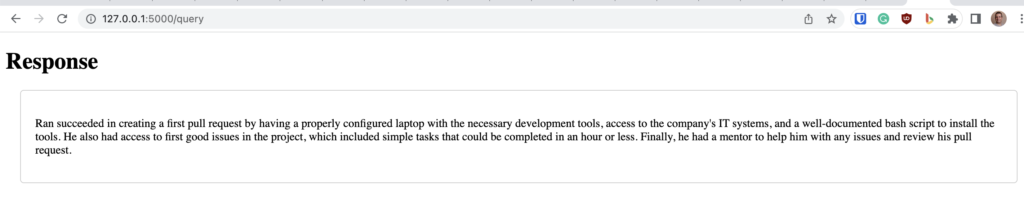
Ran Bar-Zik created his first pull request on August 2022, his first day at CyberArk.
המשימה הושגה: GPT יודע דברים חדשים. כל מה שהופיע ב-data.
יישומים
כמובן שזו רק דוגמה, אם הייתי ��שתמש בפלאגין החדש שיש בצ׳אט GPT שמאפשר לו חיפוש בווב, הוא היה מוצא את התשובה. אבל זה שימושי מאד גם לדברים אחרים – למשל למאמרים או מקורות ידע שלא נמצאים בווב. תחשבו למשל על מידע המיועד לנציגים בלבד. אם נטען את המידע הזה ל GPT או ל LLM אחר אז תהיה לנו מערכות משוכללת שבה הנציגים יוכלו להשתמש כדי לשאול שאלות במקום לקרוא לנציג בכיר.
דוגמה נוספת – ממשק ווב
הנה למשל דוגמה לממשק ווב שעוטף את הסקריפט הזה עם flask.
התקינו את flask עם:
poetry add flaskצרו קובץ server.py בתיקיה הראשית והכניסו את הקוד הזה:
from flask import Flask, render_template, request, jsonify
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
import os
from dotenv import load_dotenv
load_dotenv()
app = Flask(__name__)
index = None
persist_dir = "./storage"
data_dir = "./data"
@app.route("/", methods=["GET"])
def home():
return render_template("index.html")
@app.route("/query", methods=["POST"])
def query():
question = request.form["question"]
query_engine = index.as_query_engine()
response = query_engine.query(question)
return render_template("response.html", response=response.response)
def build_storage():
documents = SimpleDirectoryReader(data_dir).load_data()
global index
index = GPTVectorStoreIndex.from_documents(documents)
index.storage_context.persist()
def read_from_storage():
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
global index
index = load_index_from_storage(storage_context)
if os.path.exists(persist_dir):
read_from_storage()
else:
build_storage()
if __name__ == "__main__":
app.run()
צרו תיקית templates וצרו שם שני קבצים. קובץ index.html
<!DOCTYPE html>
<html>
<head>
<title>Simple Question Interface for GPT</title>
</head>
<body>
<h1>Ask a Question</h1>
<form action="/query" method="post">
<input type="text" name="question" placeholder="Enter your question">
<button type="submit">Submit</button>
</form>
</body>
</html>
צרו קובץ בשם response.html והכניסו לשם את הטקסט הזה:
<!DOCTYPE html>
<html>
<head>
<title>Response</title>
<style>
.response-container {
margin: 20px;
padding: 20px;
border: 1px solid #ccc;
border-radius: 5px;
}
</style>
</head>
<body>
<h1>Response</h1>
<div class="response-container">
<p>{{ response }}</p>
</div>
</body>
</html>
נריץ את הקוד עם:
python server.pyייווצר שרת מקומי בכתובת http://127.0.0.1:5000, תוכלו להכנס אליו ולקבל ממשק וובי פשוט ממש שבאמצעותו תוכלו לתשאל את GPT עם הקונטקסט החדש.
סיכום
כאמור, GPT לא יחליף לאף אחד את העבודה. אבל כדאי מאד לדעת להשתמש בו ביעילות וזו אחת מהדוגמאות הנפלאות ליישומים שאפשר להפעיל. זה רק מבוא, יש בדוקומנטציה של llama index דוגמאות להרחבות רבות – למשל לא להכניס את האינדוקס לקבצים פשוטים אלא למסדי נתונים מסודרים כמו מונגו או pinecone למשל וכמובן וקטורים, שלא נכנסתי אליהם כאן.
תודה רבה מאד לאלכס גלמן, ארכיטקט ראשי בסייברארק, על ההשראה והרעיון לכתוב על הנושא.




18 תגובות
היי רן.
חזק מאוד.
האם המידע שהעברת מאונדקס ונשמר אצל ה GPT כך שגם שלקריאות של משתמשים אחרים תהיה גישה למידע הזה או רק לך בעת ביצוע התהליך. האם זה נשמר לעתיד בקונטקסט של המשתמש?
באופן עקרוני, עד כמה שאני יודע – לא. זה לא נחלק עם משתמשים אחרים אבל כן נשמר ל-30 יום בשרתים של openai.
אני לא משתמש בזה כרגע למידע עסקי קריטי או רגיש. בטח שלא ל PII וחבריו. אבל למשל לדוקומנטציה שגם כך גלויה – בטח ובטח.
מדהים.
לדעתי יש לך טעות בקובץ response.html זה אותו קובץ כמו index.html.
אתה צודק! תיקנתי ותודה רבה לך ????
תודה רבה על התוכן המעולה, רן!
כתבת שהחבילה זמינה גם ב Node.js. בטוח? לא הצלחתי למצוא.
יש את זה. זה wrapper אבל בהחלט אפשר להשתמש בו.
https://www.npmjs.com/package/llama-node
רק חשוב לומר שלא יצא לי להשתמש בו אישית.
תודה רבה רן.
כתרגיל, ניסיתי לשאול את bard את אותה השאלה (בלי לאמן אותו מראש).
כאשר שגיתי באיות שם החברה, הוא סיפק מידע שנראה נכון אבל לא היה קשור למציאות (פול ראשון בשנת 2017…)
חזרתי על הנסיון בלי לשגות, וקיבלתי תשובה שנראית נכונה כולל המקור לתשובה.
.
אם לא הייתי יודע מה התשובה הנכונה, סביר שהייתי מקבל את השגויה באותה רמת אמינות … (אין פה איך להדביק תמונות).
נורא צריך להזהר עם דברים כאלו ועם טעויות 🙂 אני חושב שיצליחו לצמצמם טעויות כאלו אבל לא למנוע אותן לגמרי.
הלכתי לנסות קצת יותר לעומק. זה ממש נחמד.
אפשר לתת לו מידע ב- markdown למשל מה- KB של החברה שלכם ואז יש לכם צ׳אטבוט חכם על הנתונים של החברה.
אפשר לתת לו קבצי CSV עם נתונים ולשאול עליהם שאלות כמו ״באיזה חודש המכירות היו הכי נמוכות״ ו=״מה העקומת המכירות בחצי השנה שעברה״.
כמובן, זה תמיד תשובות בערבון מוגבל, זה איטי, וזה יקר וכנראה שכל מה שתאכילו אותו ישמש כנגדכם בסופו של דבר. אבל בהחלט שימוש מאוד מעניין למוצר הזה.
תודה על השיתוף רן
תודה רבה על הפוסט, כתוב נהדר.
שפכתי לו csv של ציוצים מהטוויטר וספר ב pdf והוא לא מצמץ, מבחינת התשובות שאני מקבלת – תוצאות מעורבות (נגיד לבסס תשובה על התרחשות בשלב מוקדם בספר ולא על מה שקרה בהמשך).
חשוב לציין בשורה שכתבת על KEY של OPENAI שזה חייב להיות בגרש בהתחלה וסוף. זה לא כל כך ברור למתחילים אני מניח.
שאלה אליך, בגרסה שלך היכן אני קובע את הפרמטרים של chatgpt למשל טמפרטורה או סוג מודל וכדו'?
מה עושים מפתחי js, שלא רוצים לעבוד עם פייתון?
ספציפית מבחינת המידע המעודכן הזמין ברשת הציבורית, אני לא מצליח להבין למה אתה מתעלם מבינג ומכל הודעה הקשורה לנושא. הרי שם המידע נלקח מהרשת בזמן אמת כולל שימוש ב-gpt-4 ואפילו לא צריך הרשמה.
הי,
הקוד רץ אבל מחזיר לי תשובות עקביות של none – רעיון למה?
אני מרגיש שחשוב לציין (ואולי לא ציינת כי זה מובן מאליו) שהמידע הנוסף הוא חלק מהפרומפט ו-GPT שוכח אותו ברגע שהוא נותן תשובה.
אם תשאל שאלת המשך באותה שיחה, הוא פשוט יקרא הכול מהתחלה. אם תשאל בשיחה אחרת, לא יהיה לו מושג על מה אתה מדבר.
כשאני מריצה את הקוד עם azure
openai.api_type = "azure"
openai.api_base = os.getenv("OPENAI_API_BASE")
openai.api_version = "2023-03-15-preview"
openai.api_key = os.getenv("OPENAI_API_KEY")
אני מקבלת את השגיאה הבאה:
openai.error.InvalidRequestError: Must provide an 'engine' or 'deployment_id' parameter to create a
מישהו יודע למה?
הי רן, מעניין מאוד!
זו פעם ראשונה שאני מנסה לבנות עם poetry.
מתקבלת הודעת שגיאה ModuleNotFoundError: No module named 'llama_index'.
pyproject.toml ו poetry.lock נוצרו בספריה context_demo וכוללים את llama_index.
אני חושד שיש לי איזושהיא טעות במבנה הקבצים – תוכל אולי להוסיף צילום או סכמה של ספרית הפרויקט?
תודה רבה!
כמובן שרפוזיטורי ב גיטהאב יהיה הכי יעיל. תודה!