ביום של כתיבת שורות אלו, ים פלג שחרר מודל עצום של LLM בעברית (בסיוע הספונסרים: חברת Arjeo).
אפשר לקחת את המדריך as is ולהריץ אותו על המחשב שלכם אם הוא חזק מספיק ויש לו כרטיס גרפי. במקרה הזה הסיכוי להסתבכות הוא לא קטן כי יש עניין של סביבות, התקנת פייתון וכו׳. במקרה הזה – אנא השתמשו ב pyenv להתקנת פייתון (המדריך הזה שלי להתקנת pyenv יסייע) ודלגו אל ״התקנת התלויות בפייתון״
הידע הנדרש: זה מדריך טכני ואני יוצא מנקודת הנחה שאם לא תדעו משהו ספציפי כמו ״מה זה טרמינל״ – תוכלו לגגל ולחפש. מה שנדרש הוא שיהיה לכם חשבון ב-AWS. אם אין לכם, זה הזמן. פותחים אותו ומזינים כרטיס אשראי. כי זה הולך לעלות לכם כמה שקלים בודדים. אני מסביר פה על פייתון, שזו שפה ממש כיפית ופשוטה ומתכנתים בשפות אחרות לא יתקשו להסתדר עם מעט הקוד שיש פה.
יצירת מכונה ב-EC2
השלב הבא הוא ליצור מכונה ב-EC2. מדובר במכונה וירטואלית שיש עליה לינוקס. המכונה הזו עולה כסף לשעת שימוש כאשר העלות יכולה להיות סנטים בודדים עד לכמה דולרים לשעה. במקרה שלנו אנחנו נצטרך מכונה חזקה יחסית שתעלה לנו כמה שקלים לשעה.
נכנס אל הקונסולה ואל ec2 ונבחר ״יצירת instance״. אנו נצטרך לבחור AMI – ראשי תבות של Amazon Machine Image. מה זה אומר? סוג של אימג׳ שממנו המכונה נבנית. יש מלא כאלו – כאלו שהם רק לינוקס, כאלו שהם לינוקס עם Node.js וכמובן כל מיני סוגים של מערכות הפעלה אחרות. יש אלפים, אני לא מגזים. . אנחנו נחפש Deep Learning – ונבחר את האימג׳ של PyTorch גרסה 2.2.0 (אם יש לכם גרסה טיפה אחרת זה גם בסדר, אבל 2 ומעלה) ונוודא שזה אובונטו. לא AWS linux.

אחרי שבחרנו את סוג ה-AMI, השלב הבא הוא להכניס פרמטרים של המכונה. החלק הכי חשוב הוא המכונה עצמה. אפשר לבחור כל מכונה אבל ה-AMI הזה עובד עם המכונות החזקות עם הגרטיס הגרפי מסוג G. אנו נבחר את אחד מהם בהתאם לתקציב. אני ממליץ על יותר מ G5.
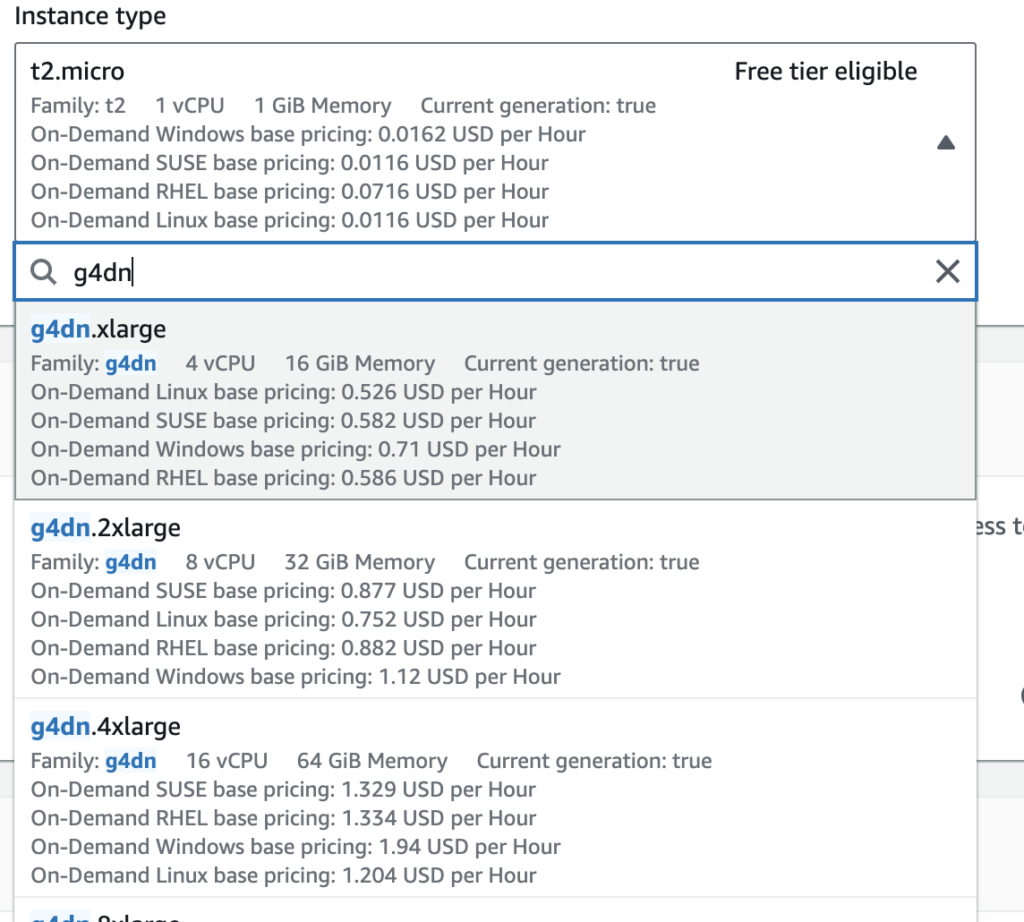
השלב הבא הוא להגדיל את כמות ההארדיסק שאנחנו צריכים. לפחות למאה ג׳יגהביט.
השלב הבא הוא לייצר את המכונה, כדאי לייצר מפתחות כדי שנוכל להתחבר מ-CLI. אבל זו בחירה שלכם.
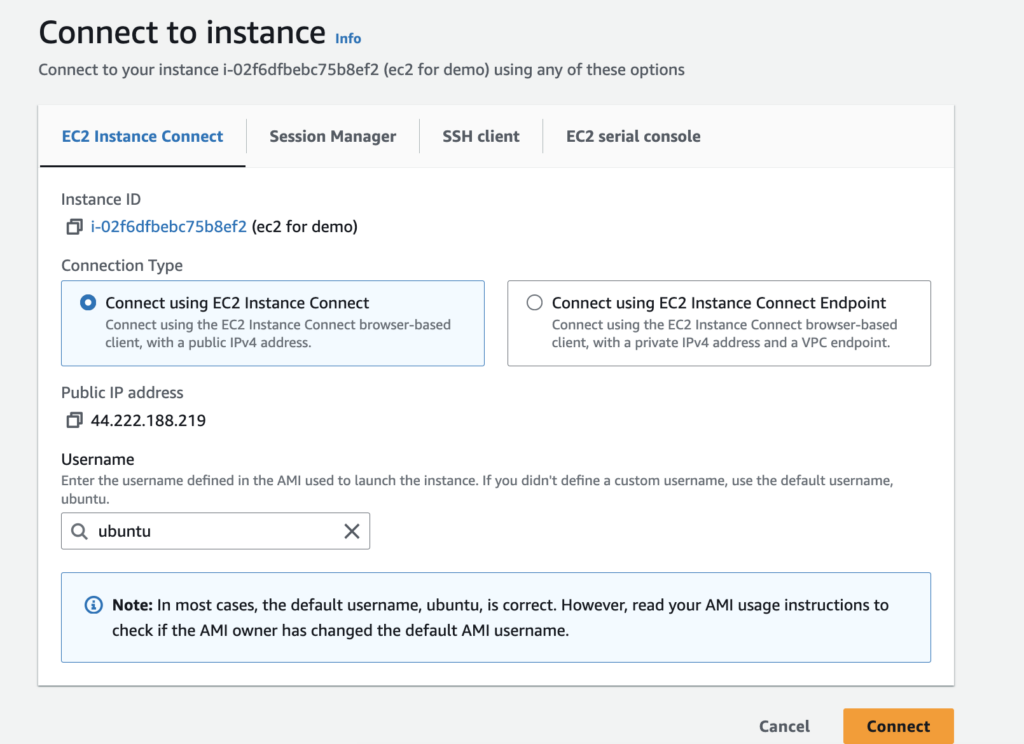
אחרי שהמכונה נוצרת, נתחבר אליה. אפשר דרך הדפדפן ואז תפתח קונסולה בדפדפן או ישירות עם SSH. אם אין לכם מושג מה זה SSH – פשוט תתחברו עם EC2 Instance Connect. הוא יפתח לכם טרמינל ישר בדפדפן.
התקנת התלויות בפייתון
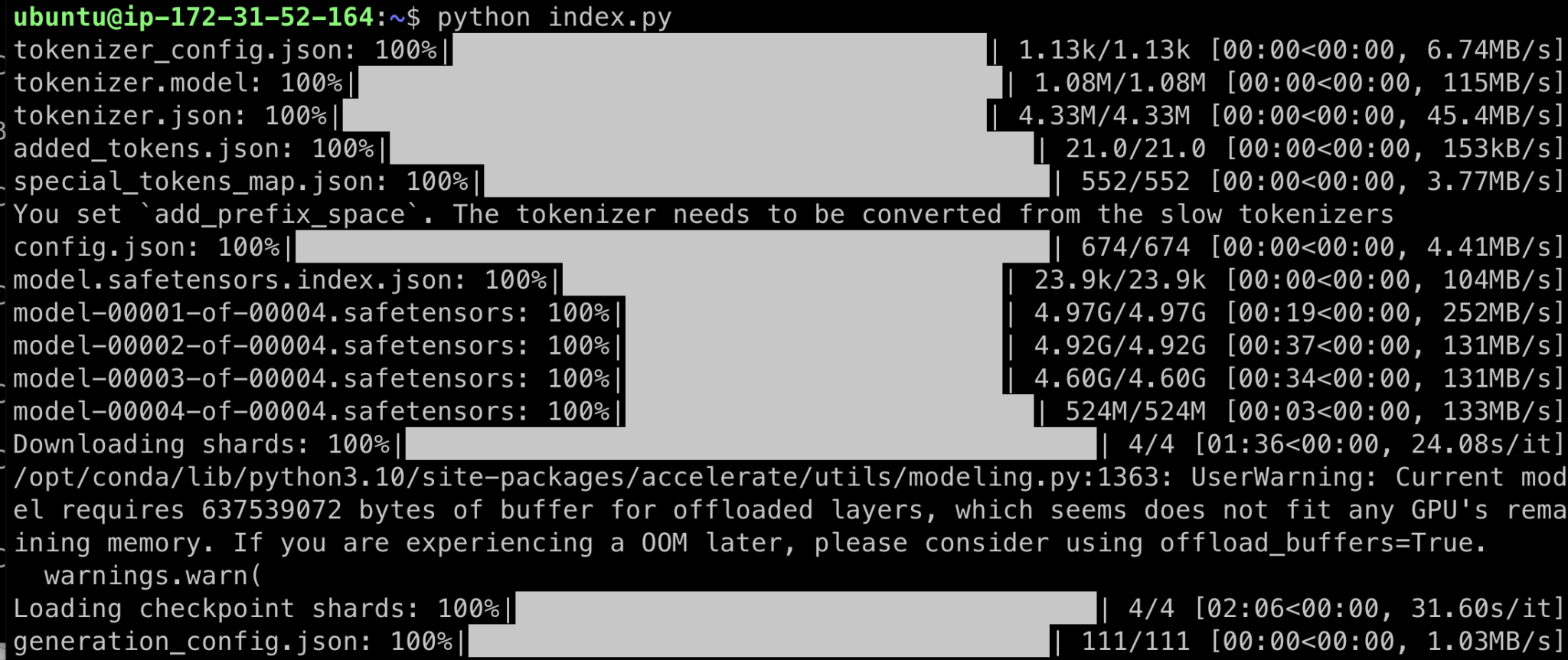
א��רי שהמכונה עולה והתחברנו לקונסולה. השלב הבא הוא להתקין את התלויות בפייתון, המכונה כבר באה עם פייתון. אני משתמש פה ב-pip לשם הפשטות. הקלידו:
pip install torch transformers accelerate sentencepiece protobufואז הקלידו על אנטר. את התלויות האלו אנו נצטרך בהמשך. יקח כמה דקות להתקנה לרוץ. אין מה להכנס ללחץ ????

אחרי ההתקנה, הגיע הזמן להכניס את הקוד עצמו! אנו נקליד:
nano index.pyונקליד את הקוד שמופיע באתר של המודל Hebrew-Mistral-7B:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("yam-peleg/Hebrew-Mistral-7B")
model = AutoModelForCausalLM.from_pretrained("yam-peleg/Hebrew-Mistral-7B", device_map="auto")
input_text = "שלום! מה שלומך היום?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
הקוד הזה משתמש ב-GPU.
נלחץ על קומנד x או קונטרול x. ה-nano, שהוא עורך טקסט, ישאל אותנו אם לשמור ואנחנו נאמר לו ״בוודאי!״ ונלחץ על y. יווצר לנו קובץ בשם index.py.
הגיע הזמן לבדוק את הקוד! אנו נכתוב:
python index.pyונשב להתבונן בהצגה! זה יקח זמן.
מה שקורה הוא שהקוד מוריד את המודל מהאתר של Hugging Face ומתחיל להריץ אותו מקומית על המחשב.
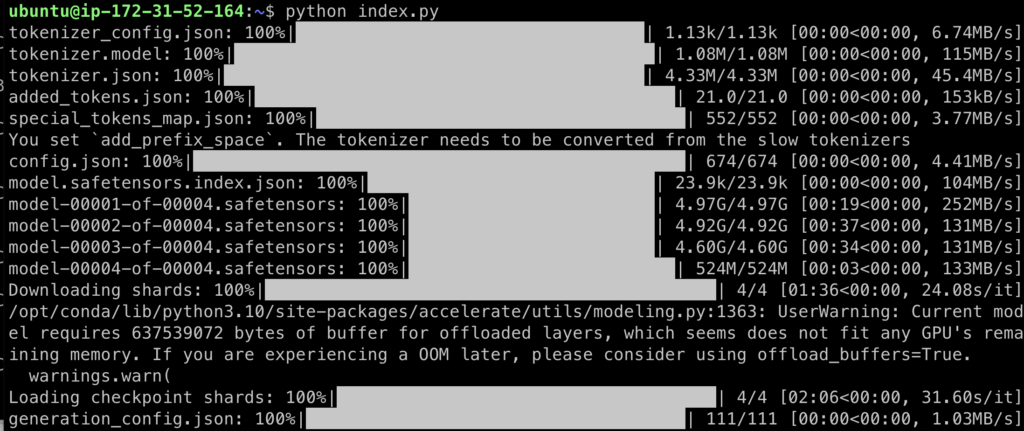
אחרי כל ההרצות והזמן, תתקבל סוף סוף תשובה לשאלה "שלום! מה שלומך היום?״!
אפשר כמובן גם להזין שאלות אחרות ואפשר לפתוח CLI שיענה באופן קבוע על השאלות מהמודל הטעון מבלי שיש צורך לטעון אותו שוב ושוב. אבל ככה בדיוק מריצים את המודל הזה, ואחרים, באופן ראשוני.
אפשר לראות שההרצה, הטעינה וההפעלה לוקחים המון זמן וזה מרגיש קצת כמו הקטע הזה ב״חזרה לעתיד 3״ שבו דוק בראון מכין קובית קרח:
אבל זו רק ההתחלה וכמובן שהרצה של מודל גדול שונה מאד מבחינת סדרי גודל ממודלים קטנים יותר והרצה של מודל לסביבת פרודקשן לא נראית ככה (בגלל זה חלק מהחברות משתמשות למשל בכלים אחרים כמו Sagemaker ולא במכונות י��ודיות, בטח ל-LLM). אבל זה נהדר למי שרוצה לשחק ולהשתעשע במודל של ים פלג ובמודלים אחרים.
אפשר כמובן להתנסות במודלים אחרים, פחות קשוחים ועצבניים. למשל, הנה מודל של ניחוש סנטימנט – האם מדובר בטקסט חיובי או שלילי.
מודל זיהוי רגש בטקסט
המודל של אביחי שריקי, שגם הוא נמצא ב-Hugging Face, הוא נהדר וגם ממש קל להפעלה – אפילו במכונה חלשה יחסית.
באותה מכונה – שכבר התקנו עליה את המודולים השונים, כל מה שאנחנו צריכים לעשות זה להשתמש בקוד הזה – אפשר לשמור אותו בשם אחר – למשל תחת hebheb.py
from transformers import pipeline
# Load the pre-trained sentiment analysis model
sentiment_analysis = pipeline(
"sentiment-analysis", model="avichr/heBERT_sentiment_analysis")
input_text = [
"אני שונא אותך"]
# Perform sentiment analysis on the input text
result = sentiment_analysis(input_text)
# Print the result
print(result)
אנו נקבל הערכה שמדובר בטקסט עם סנטימנט שלילי. אם נריץ אותו עם ״אני אוהב אותך״ נקבל סנטימנט חיובי.

אם תריצו את זה, תגלו שההרצה היא ה-ר-ב-ה יותר מהירה מאשר המודול הכבד. עכשיו אפשר לתפור סביב זה מערכת יותר רצינית.
⚠️ חשוב ⚠️
⚠️לא לשכוח לכבות את המכונה בסיום המשחקים כדי להמנע מחיובים נוספים ואם אתם לא מתכוונים להשתמש בה יותר לעולם – לעשות לה Terminate.
סיכום
כמתכנת, אני אוהב הרבה פעמים לטנף את הידיים בקוד ולראות ״איך דברים עובדים״ במקביל ללימוד התיאוריה. עולם למידת המכונה והבינה המלאכותית הוא עולם עצום, אבל לא חייבים להיות בקיאים בו כדי לשחק איתו לפחות באופן שטחי. אם תמיד התבאסתם כשראיתם שיש כל מיני מודלים שיצאו ולא הייתם סגורים על איך לבחון אותם – מכונה של EC2 יכולה להיות ממש שימושית במשחק הראשוני.






