אחת הבעיות בתחום ה-AI שיש הרבה מונחים שמזכירים למידה אנושית ואז מאד קל להאניש (מלשון להפוך לאנוש) אלגוריתמי מחשב. מאד קל לחשוב שמודלי שפה גדולים (LLM, שזה המודלים שמייצרים טקסט כמו אדם אנושי) מתנהגים או חושבים כמו בני אדם כי אנו משתמשים במונחים כמו אימון, למידה מכוונת או לא מכוונת וכמובן רשת נוירונים. הבעיה היא שהמונחים האלו אינם דומים למונחים אנושיים. אימון ממוחשב הוא לא אימון של בני אדם, רשת נוירונים שונה מנוירונים אנושיים וגם הליכי הלמידה של אלגוריתמים ממוחשבים שונים מאד.
אחת מהדוגמאות הנפלאות ביותר, שד״ר ארז ויסבארד הראה לי בזמנו, היא למידת חיזוק. אם אני אומר לכם מה היא, היא תשמע מאד מסובכת. מדובר בתחום של למידת מכונה שבה האלגוריתם לומד לעבוד בסביבה דינמית באופן שימקסם את הרווח כתוצאה מפעולה זו. בדיוק כמו שבני אדם או חיות לומדות בשלבים מוקדמים של ההתפתחות שלהם. כך אנחנו יכולים ללמד כלב לעשות את צרכיו מחוץ לבית כי בהתחלה נותנים לו עוגיה או מאכל אחר. אבל כמובן שהדמיון הוא רק על פני השטח. בפועל אלגוריתם של למידת חיזוק הוא כל כך פשוט (לפחות באופן הנאיבי שלו) שמאד קל להבין אותו אינטואטיבית ולעשות קצת די-מיסטיפיקציה לסיפור הזה.
בגדול, אנחנו מציינים בפני האלגוריתם שפעולה מסוימת היא טובה עבורו. בואו נדמי��ן שיש משחק כזה של קופים ותנינים. הם יכולים לאכול אחד את השני כמו בדמקה (באלכסון) – מי שמנצח הוא זה שהכלי שלו מגיע לסוף או זה שליריב שלו אין יותר פעולות.

אנו נשחק מול המחשב כאשר כל מהלך יימדד. אם המחשב ינצח, המהלך האחרון שלו יקבל ציון גבוה. אם הוא יפסיד, המהלך האחרון שלו יקבל ציון נמוך. כך, בשיטת האלמיניציה, מהלכים גרועים יורדים מסט האפשרויות של המחשב. בכל מצב אפשרי של הלוח, אנו מחשבים את כל המהלכים החוקיים של המחשב ונותנים לכולם ציון בסיסי. בכל פעם שהמחשב מבצע מהלך, המהלך נשמר בזיכרון. אם המחשב מנצח, הציון של אותו מהלך גדל – כך שבפעמים הבאות, יהיה לו סיכוי גבוה יותר לבחור בו. אם המחשב מפסיד, הציון של אותו מהלך קטן – מה שמקטין את הסיכוי לבחור בו בעתיד. בנוסף, אם כל האפשרויות למצב מסוים מתאפסות – כלומר מגיעים לנצחון של האדם, המודל יתחיל להעניש גם את המהלך הקודם – כדי להימנע ממבוי סתום.
בואו ונראה איך זה עובד. נניח שאני מתחיל בלהזיז את הקוף מצד שמאל קדימה. יש למחשב שלוש אפשרויות.

הוא בוחר באפשרות של להזיז את התנין הימני ביותר קדימה.
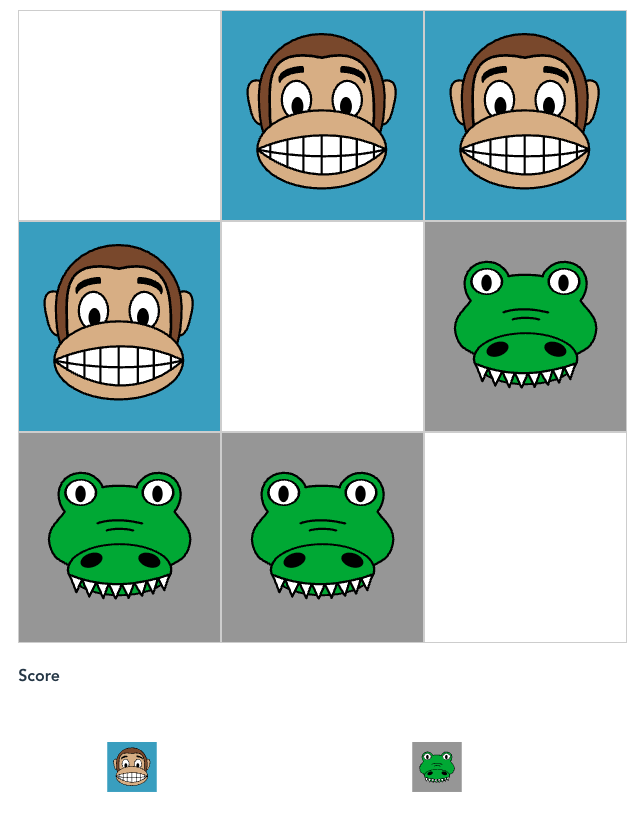
אני אוכל את התנין שיש במרכז ומנצח.
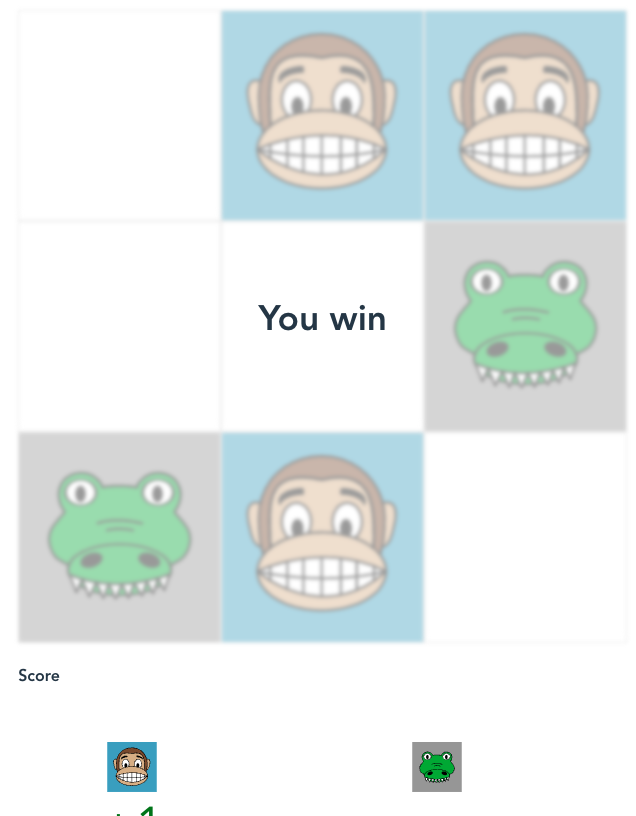
ניצחתי בשני מהלכים! המהלך הראשון בעצם עף מהחלון. המחשב כבר לא יבחר בו יותר.
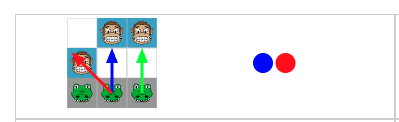
הוא יבחר בשתי הפעולות הבאות. אם הוא יזיז את התנין האמצעי קדימה, אני אוכל אותו עם הקוף מימין, לא משנה איזו פעולה הוא יעשה, הוא יפסיד. אז גם הפעולה הכחולה תעוף מהחלון. מה שישאר בסוף זו הפעולה האדומה בלבד. האכילה עם התנין האמצעי את הקוף.
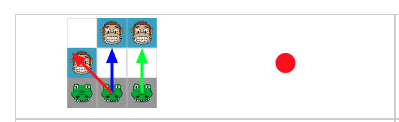
בעצם מה שעשינו כאן הוא אלימינציה. וממש קל לממש את האלימניציה הזו בלי מודלים, תהליך אימון ומילים מפוצצות. איך? קודם כל – נסו לשחק את המשחק הזה בחי! אחרי כן, אפשר להסתכל על הקוד שלו בגיטהאב וספציפית על הקוד של הלמידה. זה קוד בג׳אווהסקריפט והוא ממש פשוט (105 שורות).
המחשב מתחיל עם כל האפשרויות החוקיות שמחושבות על-ידי הפונקציה calculatePossibleMoves. בתחיל�� הדרך, כל מהלך מקבל ניקוד ראשוני זהה – מיוצג על ידי מערך ה־sweets שבו לכל מהלך יש ערך התחלתי של 1. כאשר יש תוצאה (בשורה 98-105) אם המחשב מפסיד, יש קריאה לפונקציה updateModel(false) שנמצאת ממש מורידה את ערך ה־"סוכרייה" של המהלך שבוצע, על-ידי הקטנתו ב-1.
אם המחשב מפסיד שוב ושוב עם אותו מהלך, אותו מהלך יהפוך לפחות ופחות "מושך" עד שבסופו של דבר הוא יוסר בפועל ממערך האפשרויות, כיוון שהסיכוי לבחור בו יהפוך לאפס (הסוכרייה נגמרת). כך מתבצעת האלימינציה בפועל: מהלכים גרועים פשוט "עפים מהחלון".
בנוסף, אם כל המהלכים האפשריים במצב מסוים הופכים לאפס (כל הסוכריות נגמרות), המחשב גם מעניש את המהלך הקודם שביצע כדי למנוע חזרה על אותו דפוס משחק
if (allSweetsGone && this.model[this.lastlastSituation].sweets[this.lastlastActionTaken] > 0) {
this.model[this.lastlastSituation].sweets[this.lastlastActionTaken]--;
}המחשב בוחר את הנתיבים שבהם הציון הוא לא אפס.
גם אם לא הבנתם את הקוד, זה בסדר גמור. מה שחשוב הוא להבין שלפעמים רעיונות מורכבים מאד שממש גורמים לכל הסיפור להיות וודו, הם פשוטים. נכון, מדובר בתסריט פשוט ונאיבי וכמובן שהראיתי כאן מימוש מאד מאד מאד פשוט של Reinforcement Learning וכמובן שבשימושים אמיתיים אנחנו מגיעים לרמות אחרות וטכניקות אחרות. אבל זה לא קסם, זו מתמטיקה וקוד. הקוד לא ״לומד״ כמו איזה סקיינט עתידנית. בבסיס זה קוד שכולנו מכירים ואוהבים.