
הפוסט הזה הוא חלק מהסדרה של איך הופכים פרויקט ל AI Ready ועל המשמעויות של לעבוד על פרויקט קוד בתקופה הנוכחית שבה משתמשים בעיקר בכלי בינה מלאכותית על מנת לכתוב את הקוד. הפוסט הקודם היה על הוקים, הפוסט הנוכחי הוא על שימוש נבון ב-Plan mode כדי למזער טעויות, לעבוד יותר יעיל ולאפשר בדיקה של הקוד טוב יותר.
אין כבר כמעט מתכנת שאינו כותב קוד באמצעות עורך קוד מבוסס LLM. אבל יש דרכים שונות לכתוב ולהיות יעילים. אחת הדרכים שמשתמשים בה פחות מדי היא Plan Mode והיא זמינה בכל עורך קוד (בין אם מדובר בקורסור, קלוד קוד או קודקס). המוד הזה של התוכנית הוא בדיוק כמו אייג׳נט. כלומר הוא עובד באופן אופרטיבי, הוא יכול להשתמש בכלים וביכולות שונות אבל, וזה אבל גדול, הוא לא מבצע פעולות כתיבה, מחיקה או עדכון. לא של הקוד ולא של חלקים אחרים כמו דאטהטבייס. גם אם יש לו גישה לכלים כאלו, באופן עקרוני הוא לא אמור לערוך או לשנות מידע.
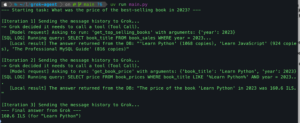
התוצר של ה-Plan Mode הוא קובץ טקסט שנקרא תוכנית. את קובץ הטקסט אפשר לקרוא ואפשר גם להמשיך ולהתכתב איתו עד שהתוכנית תהיה לשביעות רצונכם. זה חשוב כי זה מאפשר לכם להבין מה קורה שם ולהשפיע על פעילות האייג׳נט עוד לפני שהוא רץ. אפשר להוסיף חלקים מסוימים כמו למשל גיבוי או שמירה, בדיקות נוספות לפני צעדים מסוכנים או בכלל – מאפשר לכם להבין מה קורה שם בדיוק לפני שהאייג׳נט מתחיל לרוץ ולכם להמנע מקריאות השבר של ״מה עשית?!? זה לא זה!!!״.
איך עושים את זה? בדרך כלל בממשק יש אפשרות לשנות ל Plan mode או אפילו לבקש מהסוכן עצמו שיעבור ל Plan mode. כשהוא במוד הזה אפשר לבקש ממנו מה צריך לעשות.

התוצר יהיה קובץ md שניתן גם לשמור, להעתיק או לחלופין לערוך ידנית אם אתם רוצים.
איך כותבים תוכנית טובה
בגדול, תוכנית טובה מתחילה בכם 🙂 מה הכוונה? אתם צריכים להבין מה אתם רוצים ומה אתם צריכים ולנסח את זה בבהירות. שווה להשקיע כמה דקות בחשיבה. אפשר לכתוב מה המצב הרצוי ומה המצב שאתם מגיעים אליו ועדיף שיהיו הגדרות מדויקות למה אתם צריכים שיהיה בסוף. ההגדרות האלו נקראות Definitions of Done או DoD ועדיף שהן יהיו מנוסחות היטב. למשל הנה DoD:
״הוספת לוג שקורה כאשר יש שגיאות בקריאת קבצים״
זה כמובן אחד לא מוצלח במיוחד. למה? ההנחיה הזו כללית מדי. האייג'נט עלול לבחור להשתמש ב-console.error פשוט במקום בספריית הלוגים הרשמית של הפרויקט. הוא לא יודע איזה מידע להדפיס (רק את הודעת השגיאה? את ה-Stack trace? את שם הקובץ שנכשל?), איפה בדיוק לתפוס את השגיאה, והאם הוא צריך לטפל בה או רק לתעד אותה ולהמשיך הלאה.
לעומת DoD איכותי:
- כל קריאת קובץ בפונקציית
readFileContentsתעטוף בבלוקtry-catch. - במקרה של שגיאה, ישתמשו ב-Logger של המערכת (
logger.error) כדי לתעד את האירוע. - הודעת הלוג חייבת לכלול את הטקסט המדויק:
[File Read Error], את נתיב הקובץ המלא (filePath), וא את הודעת השגיאה המקורית (error.message). - לאחר רישום הלוג, הפונקציה תזרוק את השגיאה הלאה (re-throw) כדי לא לבלוע אותה בשקט.
- כתוב בדיקות יחידה
זה כמובן הרבה יותר מסודר ומודל הטקסט בנוי לעבוד יותר טוב עם סעיפים. אגב, אף אחד לא אמר שאתם לא יכולים להעזר ב-LLM כדי לבנות את ה-DoD הזה. אבל אם באים עם אחד כזה, המודלים מגיבים יותר טוב וגם לכם קל מאד לעבוד עם התוכנית ולוודא שהיא באמת עושה את מה שאתם רוצים.
בדיקה של התוכנית
לפני שאני מתחיל לריב עם הסוכן, אני יכול לבקש ממודל אחר לבדוק את התוכנית המוצעת ולתת הערות. אני אוהב לערבב בין המודלים השונים כי הרבה פעמים בגלל המשקולות ונתוני האימון למודל אחד יכול להיות הצעה שלמודל אחר איו. לחלופין, אני יכול להעתיק את הטקסט ולהדביק בצ׳אט עם גרסאות של LLM שאולי אין לי גישה ברגיל אליהן.
חיבור תוכנית לכלים חיצוניים
אחרי שהתוכנית כבר הוכנה, או אפילו במהלך ההכנה, יש גישה לכלים חיצוניים לקריאת מידע. אפשר לחבר לכלי קריאת לוגים, לכלי ניטור, לאיזה כלי שאתם רוצים. אני למשל מבקש תמיד לקרוא מידע משלים מהכלי לטיפול בבאגים (ג׳ירה, או גיטהאב issues או ווטאבר) ומוודא שיש לו גישה.
איטרציות ובקרה
במהלך הכנת התוכנית, כדאי מאד לדרוש ולוודא שיהיו כמה שיותר צעדים בתוכנית. למה? כי המוח האנושי לא מסוגל להתמודד עם כמות המלל שהמודלים האלו יוצרים ופירוק כל תוכנית לצעדים קטנטנים מאד עוזר גם בהבנה של התוכנית עצמה וגם אחר כך בבקרות. אני לא אוהב להתמודד מול פול ריקווסטים גדולים ועצומים של מאות קבצים. אולי בהתחלה ב Initial commit בתחילת הפרויקט אבל בפרויקטים מורכבים אני מבקש ממנו לפרק את התוכנית לצעדים קטנים ככל הניתן ולציין בפירוש שכל צעד הוא פול ריקווסט נפרד עם הסבר.
אחרי שהתוכנית מושלמת, אני מבקש מה-LLM, לפני הביצוע, ליצור טיקט למשימה אבל מתחתיו טיקט נוסף לכל צעד. זה יכול להיות אפילו עשרות כאלו. אחרי שיש לי טיקטים שבכל אחד מהם כתוב בדיוק מה לעשות, זה נותן עיגון גם לי וגם ל-LLM וגם מאפשר לי לבדוק את התוצר בקלות רבה יותר.
תוכנית ביוקר, ביצוע בזול
מה שכדאי לזכור הוא שאנחנו יכולים לייצר את התוכנית עם מודל יקר מאד שיפרט באופן מדוקדק מה לעשות ואיזה כלי להפעיל. התוצר של מודל חזק ויקר הוא מצוין, אבל אחרי שנייצר את התוכנית על הצעדים ונעשה איטרציות ונראה שהכל לשביעות רצוננו, נוכל להפעיל מודל זול כדי שיישם את צעדי התוכנית. בשביל למשל להפעיל כלי שיתחבר ל SFTP או ישלוף לוג מ AWS אנחנו לא צריכים את סונט גרסה 445 טוקן בדולר אלא אפשר להשתמש ב״קומפוזר, מיליארד טוקנים בסנט״.
אם פירקתם את הבעיה לחלקים קטנים, אז הסיכוי שהמודל הזול יתבלבל, יהזה או יטעה, הוא קטן. אבל, כדי למזער את הסיכון שזה יקרה, יש לי סקיל שמופעל בסיום כל push שמפעיל סאב אייג׳נט שעורך בדיקות על הקוד שנכתב. בדיקה אחת היא לוודא שהקוד שנכתב מתאים במאה אחוז למה שכתוב בטיקט הקצר שמתאר אותו. זה עולה קצת טוקנים, אבל מבטיח לי שאין הפתעות עוד לפני שאני בודק את הקוד בעין.
אם המילה סאב אייג׳נט מלחיצה אתכם, לא צריך להלחץ. זה פשוט סקיל שיוצר אייג׳נט חדש שעושה משימה אחת מוגדרת. מה המשימה? להכנס ולקרוא את הטיקט ולוודא שהקוד אכן תואם לטיקט.
האם צריך לבחון כל קוד בעין אנושית?
הדעה שלי, נכון לעכשיו? כן. אני אעשה את המקסימום כדי לוודא באמת שבקוד שאני בוחן יהיו מינימום טעויות בסיסיות ופשוטות ושהקוד באמת מוגבל למה שהוא צריך לעשות והשינויים הם מה שאני צריך לראות. האם כל שינוי וכל אות ייבחנו באופן מאד מאד קפדני? לא בטוח. אבל כן ייבחנו. בנקודות רגישות יותר הנוגעות למשל לאלגוריתמים קריפטוגרפיים, דיפלוימנט או דברים שיכולים להשפיע על העלות? אני אסתכל יותר. הפירוק של התוכנית והצעדים השונים יאפשרו לי לעשות את זה.
סיכום
תוכנית טובה היא בסיס לעבודה נכונה עם LLM וכדאי להכיר ולעבוד עם זה. אולי לא לכל פיצ׳ר בסיסי אבל לשינויים גדולים? אני מתקשה לראות איך לא עובדים עם המוד הזה ועבודה נכונה וחכמה איתו מאד מסייעת.




2 תגובות
כל כך נכון. רק נגעת בקצה הקרחון… אבל בהחלט "קשה באימונים, קל בקרב…"
מאחר ו ה SPEC שאתה נותן בשפה טבעית – מתחיל להיות ארוך (קבצי md ודומיהם)
ויכול להגיע למגבלות המודל
השאלה היא מה הארכיטקטורה הנכונה של פרויקט מחולק למודולים שמחולקים
למשימות כמו אתה שהצגת?
ואיך להגדיר סקילים שיחסכו ממנו?
יהיה מאמר?
Trước giờ mình ít comment nhưng thấy 188v link dùng ổn nên muốn chia sẻ thêm cho mọi người tham khảo. TONY06-25