האייטם המקורי פורסם בהארץ – פה מוצגת הרחבה שלו והסבר טכני.
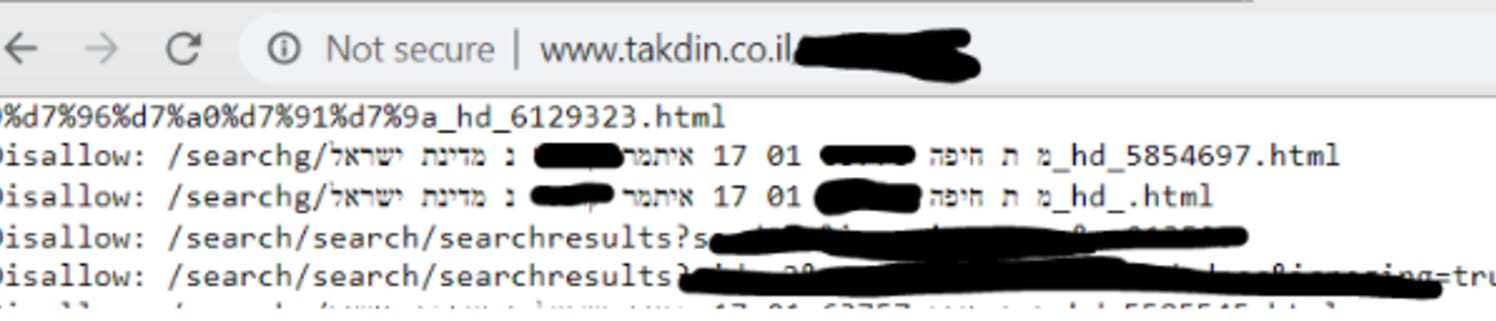
כל פיצ׳ר חביב כלשהו שמפתחי ווב משתמשים בו, מתישהו מנוצל על ידי פושעים למטרות נלוזות. והיום? היום robots.txt. מכירים אותו? זה קובץ הנחיות קטן שיש כמעט בכל אתר ומנחה את מנועי החיפוש להתעלם מדפים מסוימים. למה? כי יש דפים שאין טעם לסרוק. דף הלוגין למשל, או דפי ארכיון כפולים. שימו לב למשל לאתר וורדפרס.קום ולקובץ שלו: https://wordpress.com/robots.txt שמפרט בו דפים שהוא לא רוצה שיוצגו בגוגל.
הגיוני, לא? הדפים האלו, אגב, הם חלק ממה שנקרא ה-deep web. שם מפוצץ ומפחיד למשהו ממש פשוט: דפים שאי אפשר למצוא אותם בגוגל/מנועי חיפוש אחרים. כמו הדפים המפורטים בקובץ הזה, או מסך הניהול באתר הזה, או גרסאות כפולות של המאמרים בארכיון, תוצאות החיפוש במנוע החיפוש הפנימי באתר וכו׳ וכוק. לא כזה נורא, נכון? זה בסופו של דבר פתרון טוב מאוד שמנהל את איך שהאתר שלנו נראה במנוע החיפוש.
מה הבעיה? שהרבה מתכנתים שוכחים שכל אחד יכול לגשת לקובץ ולא רק מנועי חיפוש ונוהגים ��שים שם קישורים לדפים שמסגירים מידע שלפעמים הוא קריטי. מה זה מידע קריטי? מ-API שעדיף שלא יהיה פתוח ועד כתובת של הממשק הניהולי. אבל יכול להיות שם מידע יותר קריטי, אישי וחשוב. למשל כמו מידע שמופיע באתר תקדין לייט שבו אשתמש כדוגמה לחולשה הזו (הם תיקנו את החולשה ומהר, ראוי לציין).
את אתר תקדין לייט. אתם מכירים גם אם אתם לא עורכי דין.
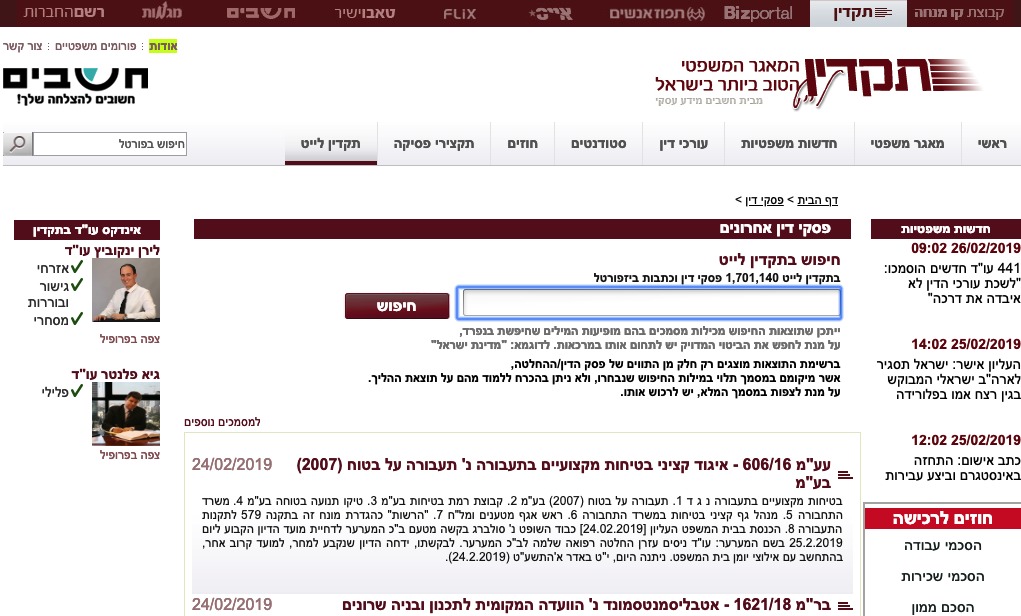
למה? כי כשאנחנו מחפשים שם של מישהו (מועמד לעבודה, בעל מקצוע, שותף) בגוגל – תקדין יציג לנו את שמו אם יש פסקי דין שמציגים את שמו. אם נרצה לחטט הלאה, נצטרך לשלם כסף על מנוי לתקדין או גישה מזדמנת. מזה האתר מרוויח. לגיטימי.

אבל האתר מרוויח מעוד משהו: הוא מקבל כסף מהסרה של שמות מהארכיבים שלו. גם עד כאן הסיפור לגיטימי. למרות שהיו לא מעט עניינים וסיפורים סביב העניין הזה.
אבל איך תקדין הסירו את השמות של האנשים? חוקר האבטחה (המורשה! יש לו תעודה) מייקל אנג׳ל גילה וגם הלשין לי: תקדין הסירו את התוצאות מהאתר, אבל הוסיפו אותן אל… ה-robots.txt שלהם כדי שגוגל לא יציג את התוצאות. כך כל אחד היה יכול לקבל גישה מלאה אל השמות של האנשים שששילמו כסף על מנת להסיר את עצמם. מפה? מפה החגיגה יכולה רק להתחיל.
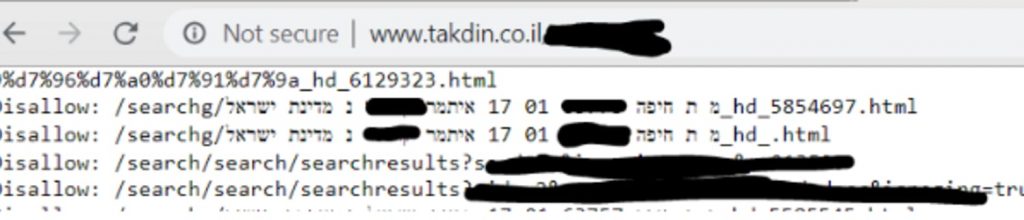
זו לא חולשת האבטחה הכי מחרידה בעולם, אבל היא דוגמה מדהימה לאיך עצלנות או אפילו סתם חוסר ידיעה יכולה לגרום לחולשות ובמקרה הזה להפרת פרטיות וגם פתח לצרות. מי ששילם על הסרת השם שלו מתוצאות תקדין במנוע החיפוש לא רצה להופיע ברשימה מסוימת שגלויה לכל, נכון?פשוט דוגמה נהדרת לחולשה נפוצה. הנה, עכשיו גם אתם יודעים 🙂
מה עושים נגד הסיפור הזה? ראשית, אם יש לכם נתונים רגישים, אל תשימו אותם ב-robots.txt. ניתן להציב בראש עמודים שאתם לא רוצים שייסרקו את תגית המטא הפשוטה robots.
<meta name="robots" content="noindex" />או לחלופין, ב-response לשים header בתגובה של השרת לעמודים שאתם לא רוצים שייסרקו, משהו בסגנון הזה:
X-Robots-Tag: noindexיש תיעוד מלא במדריך המפתחים של גוגל שמסביר על זה.
עבודה עם גוגל, או קידום אתרים בלשון העם – היא עבודה לא פשוטה. ללא ספק הנחיה של מקדם היתה יכולה לסייע פה.


5 תגובות
שאלה – אם יש נתונים רגישים, למה לא פשוט להוריד אותם מהאתר (ולשמור גרסה אופליינית שלהם)?
הרי אם למישהו היה לינק או בוקמארק לנתונים הללו, גם אם יוסיפו את התגית הזאת, הלינק עדין יעבוד…
כי לוקח זמן (לפעמים המון זמן) למנוע החיפוש להוריד את החומר הזה. כלומר מי שיחפש את השם יראה שיש תוצאה, ילחץ ויגיע לדף 404 אבל הוא יוכל לטעון את התוצאה מ-cache של הדפדפן.
מה CACHE של גוגל
לא של הדפדפן
מעניין!
מצחיק שהם עדיין השאירו את זה ככה במקום לפתור באמת ברמת העמוד.. ואפילו אחרי שזה פורסם, זב די חובבני מצידם.
הם יכלו גם לבקש מגוגל הסרת תוצאות אל כל כך היו רוצים להשקיע