במאמר הקודם דיברנו על Aggregation. במאמר הזה נדבר על Replication. באופן עקרוני, הנושא הוא רחב הרבה יותר ממאמר אחד והוא הרבה יותר בקטגוריה של ה-DBA מאשר של המפתח, אבל זה נחמד לדעת, להתנסות וקצת להכיר את התחום. במיוחד למי שיודע כמה זה קשה ב-MySQL.
באופן עקרוני, כאשר יש לנו מסד נתונים ואפליקציה שעובדת מולו, הכל מעולה. אבל מה קורה אם מסד הנתונים נופל? בדרך כלל זה מה שקורה זה משהו חינני כזה:
איך אנחנו מונעים כזה דבר באפליקציה שלנו? בדיוק בשביל זה MongoDB מאפשר לנו לעשות replication. כלומר כמה instances של MongoDB שמגבים אחד את השני באופן פשוט. ה-instances האלו יכולים לשבת באותה מכונה (קצת טיפשי אבל מעולה לתרגולים) או על מכונות שונות.
אנחנו נדבר על הקונספציה של Replication ונתרגל על סביבה לוקלית.
באופן עקרוני, אנו עובדים עם primary MongoDB שהוא בעצם המאסטר שלנו. מולו אנחנו כותבים וקוראים. יש לנו גם Secondaries שיכולים לקרוא מידע בלבד. אם ה-Primary נופל, ישנו תהליך שנקרא 'הצבעה' ובו ה-Secodaries בוחרים את ה-Primary.
(אפשר להכניס גם חבר שאינו Primary או Secondary שנקרא Arbiter והוא זה שמחליט מי ה-Primary. הוא לא מכיל עותק של הנתונים ולא נדבר עליו כאן).
הנה דיאגרמה מתוך הדוקומנטציה (המצויינת, שווה לקרוא) בנושא.
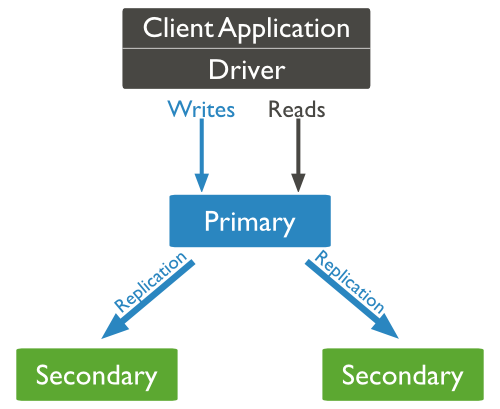
באופן עקרוני אנו זקוקים לשרת MongoDB. השרת הזה מוקם אוטומטית אם אנו יוצרים אותו כשאנו עובדים בסביבת PHP (כחלק ממודול MongoDB שדיברנו עליו בחלק על MongoDB ו-PHP) או שאנו יוצרים אותו ידנית אם אנו עובדים עם Node.js למשל.
יצירת שרת הולכת ככה:
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
הרצת השורה הזו מאפשרת לנו להריץ כמה שרתי Mongo שנרצה.
איך נוכל לסמלץ את זה אצלנו בסביבה לוקלית? מאוד מאוד פשוט. קודם יוצרים את התיקיות:
sudo mkdir -p /srv/mongodb/rs0-0 /srv/mongodb/rs0-1 /srv/mongodb/rs0-2
ואז יוצרים את השרתים – אחד לכל תיקיה:
sudo mongod --port 27018 --dbpath /srv/mongodb/rs0-0 --replSet rs0 --smallfiles --oplogSize 128
sudo mongod --port 27019 --dbpath /srv/mongodb/rs0-1 --replSet rs0 --smallfiles --oplogSize 128
sudo mongod --port 27020 --dbpath /srv/mongodb/rs0-2 --replSet rs0 --smallfiles --oplogSize 128
כל שורה כמובן מורצת בחלון נפרד. כי
מה שחשוב הוא שאני קובע את הפורט שבו אני מפעיל את השרת (לא חיוני אם אני מרים כל שרת במכונה אחרת). הכי חשוב הוא replSet rs0 כאשר ה-rs0 זה הזיהוי שלי.
–smallfiles –oplogSize 128 זה על מנת לשמור על ה-instaces קטנים – שהמכונה שלי לא תמות.
על מנת לוודא שהשרת תקין, אפשר להכנס ל: localhost:27018 עם הדפדפן ולראות משהו כזה:
It looks like you are trying to access MongoDB over HTTP on the native driver port.
עכשיו, אנו ניכנס אל השרת הראשון שהוא יהיה ה-Primary שלי.
mongo --port 27018
ובו אני אבצע את הקינפוג. כל הקינפוג נעשה באמצעות rs (שזה ראשי תיבות של Replica Set). קודם כל, קובץ הקונפיג הולך כך:
rsconf = {
_id: "rs0",
members: [
{
_id: 0,
host: "YOUR_IP:27018"
}
]
}
ה-host זה ה-IP של המכונה שלכם. זה יכול להיות שם המכונה. אחרי זה אנו מכניסים את קובץ הקונפיגורציה כך:
rs.initiate( rsconf )
אם הכל תקין, נקבל משהו כזה:
{ "ok" : 1 }
עכשיו נוכל להוסיף את ה-secondaries:
rs.add("YOUR_IP:27019")
rs.add("YOUR_IP:27020")
איך יודעים שהכל תקין? קודם כל אפשר להציץ בלוגים (הם מה שמודפס בטרמינלים השונים, היכן שהקלדתם את פקודת פתיחת השרת) או, באמצעות הפקודה rs.status. למשל משהו כזה:
rs0:PRIMARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2014-10-16T13:35:37Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "10.0.0.5:27018",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 359,
"optime" : Timestamp(1413466397, 1),
"optimeDate" : ISODate("2014-10-16T13:33:17Z"),
"electionTime" : Timestamp(1413466179, 1),
"electionDate" : ISODate("2014-10-16T13:29:39Z"),
"self" : true
},
{
"_id" : 1,
"name" : "10.0.0.5:27019",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 178,
"optime" : Timestamp(1413466397, 1),
"optimeDate" : ISODate("2014-10-16T13:33:17Z"),
"lastHeartbeat" : ISODate("2014-10-16T13:35:35Z"),
"lastHeartbeatRecv" : ISODate("2014-10-16T13:35:36Z"),
"pingMs" : 0,
"syncingTo" : "10.0.0.5:27018"
},
{
"_id" : 2,
"name" : "10.0.0.5:27020",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 140,
"optime" : Timestamp(1413466397, 1),
"optimeDate" : ISODate("2014-10-16T13:33:17Z"),
"lastHeartbeat" : ISODate("2014-10-16T13:35:37Z"),
"lastHeartbeatRecv" : ISODate("2014-10-16T13:35:37Z"),
"pingMs" : 0,
"syncingTo" : "10.0.0.5:27018"
}
],
"ok" : 1
}
אם תיצרו db, collection ו-documents. הם יווצרו גם בשאר מסדי הנתונים! נסו ותהנו!
העבודה מול ה-Replica Set תלויה מאוד בצורת העבודה שלכם. עם Node.js למשל, עושים את זה ככה עם ה-Mongodb native. אם אתם עובדים עם PHP, אז יש הסבר מלא איך עובדים עם ה-replica set בדוקומנטציה.
גם אתם יכולים לתרגל את ה-replica set.
חשוב מאוד להבין ש-replication רק עוזר לשמירת התקינות של הנתונים ולשימורם. סביבת פרודקשן שמשתמשת ב-replication תהיה הרבה יותר יציבה וטובה.
Sharding זה לא replication אלא דרך לחלק את מסד הנתונים על פני מספר מכונות. אנו לא מכסים את sharding במדריך זה.
במאמר הבא, אנו נדבר על RoboMongo, שהוא כלי UI לניהול מסדי נתונים של MongoDB.