אחת הבעיות הקשות שיש ב-LLM בין היתר הוא נושא ה-evaluation. איך אנחנו מבצעים השוואות בין מודל אחד לשני או בין כמה מודלים או אפילו בין פרומפטים או דרך לבצע פרומפטים. זה קריטי במוצרים שמשתמשים ב-LLM בבסיס שלו. לא כל המודלים נולדו שווים, יש כאלו שטובים במשימה מסוימת ויש כאלו שפחות. יש כאלו שטובים במשימה מסוימת לעומת אחרים אבל הם עולים יותר מדי. וגם אם התפקסנו על מודל, לפעמים אנחנו רוצים לבדוק יעילות של פרומפט אחד לעומת השני. זה צורך ממשי לאורך כל חיי המוצר – מהפיתוח עצמו, שבו אנו מתלבטים באיזה מודל לבחור ועד בתהליך הבדיקות שלנו כדי לוודא שאין רגרסיה וכמובן כאשר משדרגים מודל או משנים אותו. כדי להוסיף על השמחה, הכל גם לא דטרמניסטי.
כשהיה לנו פרויקט כזה בסייברארק, רועי בן יוסף, שהוא ארכיטקט תוכנה בכיר יחד איתי בצוות וגם אני היינו צמאים לכלי כזה, אבל לא מצאנו משהו פשוט. כלומר משהו שאפשר לתקתק ב-CLI ושיהיה גם גמיש מספיק לכל מה שאנחנו רוצים (בין אם לבדוק איזה מודל שנרצה כולל להשוות בין ספקים שונים, לבדוק פרומפט או לבדוק מימוש בקוד) אבל גם קל לשימוש. אז רועי יצר כזה פרויקט. לא מאד מסובך. הוא היה כל כך מוצלח שאמרנו שחייבים להוציא אותו בקוד פתוח והנה, הגענו לנקודה שבה אנחנו מוציאים אותו בקוד פתוח.
לפרויקט יש דוקומנטציה נרחבת, אבל אני מאמין בללמוד דרך הידיים ובפוסט הזה אני אתמקד בלהשוות בין פרומפטים שונים. הוא מצריך uv + python.
התק��ה
צרו תיקיה ריקה, הכנסו עם הטרמינל אל התיקיה והקלידו:
uv init
uv venv
uv add simpleval
uv run simpleval initעכשיו אנחנו נכנס לשאלון אינטראקטיבי, נקליד שם של תיקיה שתהיה הבדיקה הראשונה שלנו. זה לא באמת קריטי כי אפשר למחוק אותה ולייצר אחרת. הבה ונקליד gpt35nano
אחר כך נצטרך לבחור את שם ה-LLM as a judge ואת הספק שמאחוריו, זה ה-LLM שמבצע את ההערכה, גם פה זה לא קריטי כי אפשר לשנות את זה בקלות אחר כך. אז נבחר open_ai ו-gpt4.1. אם הוא מציק לנו על זה שחסר OPENAI_API_KEY אפשר להתעלם בשלב זה. מפה כמה אנטרים לבחירות המחדל וזהו. יש לנו תיקיה ואנחנו יכולים להתקדם. סליחה שאני לא מפרט יותר מדי על האפשרויות אבל אנחנו נשנה אותן בהמשך וקל לשנות אותן.
התרחיש שלנו – מוצר שנשתמש בו להשוואה.
המוצר שלי הוא מוצר קטן שמסכם הסכמים משפטיים. הקלט הוא הסכם משפטי (באנגלית) והפלט הוא סיכום. אני אשווה בין שני פרומפטים שונים לסיכום כדי לראות מה יותר טוב.
בשביל השוואה צריך מה שנקרא Golden set. משהו שאני יכול להשוות אליו. אפשר לומר שההתנהגות המושלמת של ה-LLM. במקרה שלנו זה יהיה הסיכום המושלם. אני יכול להשתמש בבני אדם כדי לבצע את המשימה הזו, או לפחות בבדיקה של בני אדם וטיוב של הסיכום. העניין הוא שיש לנו דאטהסט מושלם עם תוצאות מושלמות. כזה שאנחנו שואפים אליו. צריך שהוא יהיה מקיף אבל לא מקיף מדי. במקרה שלי, JSONL (לא JSON, שימו לב!) שהשם שלו הוא ground_truth.jsonl שבו בכל שורה יש:
name – שם עבור בדיקת התוצאות (לא קריטי לבדיקה, זה רק עבורי – אבל זה חייב להיות ייחודי. אפילו test1,test2 וכו׳)
description – תיאור עבור בדיקת התוצאות (לא קריטי לבדיקה, זה רק עבורי)
expected_result – זה הגביע הקדוש – התוצאה המושלמת מבחינתי שהלוואי שהיה LLM שמספק אותה. פה יש חשיבות גדולה לאדם שיסתכל על זה.
payload – לא חובה, אובייקט שיש בו שמות של קבצים. במקרה שלי זה מסמכי ה-txt של ההסכמים המשפטיים, אב זה יכול להיות גם תמונות, docx, אקסלים, מה שתרצו. אם אתם לא צריכים לבדוק קבצים והשאילתות שלכם ל-LLM לא כוללות קבצים, אז אין צורך בזה.
זו העבודה הכי רצינית, להכין את הדאטהסט הזה. במקרה שלי – עשרה מסמכים משפטיים באנגלית ועשרה סיכומים שסטודנטים למשפטים הכינו על המסמכים האלו. כך אוכל לבדוק מול המידע הזה.
המודל ששופט – LLM as a Judge
זוכרים את ההגדרות שהגדרנו בהתחלה ואמרתי שזה לא חשוב? אז הן נמצאות בקובץ הגדרות config.json שיש בו דבר אחד שחשוב לשים לב אליו – המודל שמבצע את השפיטה. הרי כאשר נריץ את השאילתות שלנו, אנחנו צריכים שיהיה מי שיגיד לנו אם התוצאה מדויקת כן או לא וזה מודל LLM – אז חשוב דווקא פה לבחור אחד טוב ועקבי שאתם סומכים עליו. עד כמה שאפשר לסמוך על LLM. כאן זה יהיה המודל שבחרנו בהתחלה אבל אפשר לשנות את השם והספק. מי אמר שחייבים GPT-4.1?
{
"name": "example_eval",
"max_concurrent_judge_tasks": 10,
"max_concurrent_llm_tasks": 10,
"eval_metrics": [
"completeness",
"correctness",
"relevance"
],
"llm_as_a_judge_name": "open_ai",
"llm_as_a_judge_model_id": "gpt-4.1",
"override": {}
}השלב הבא הוא ליצור תחת תיקית testcases תיקיה נוספת עם שם המבחן הראשון שלנו. נתחיל למשל עם gpt 3.5. מדובר במודל עתיק יומין אבל… הוא מאד מאד מאד זול, אולי הוא מספיק טוב למשימה הזו? אני צריך לכתוב את קובץ הבדיקה. הקובץ הזה בגדול צריך לקרוא ל-LLM, לבצע את הקריאה כפי שאני רוצה עם הפרמטרים שאני רוצה ואז להעביר את התוצאות לשופט כאשר כל מה שיש ב-ground_truth נקרא.
יש בקובץ שתי פונקציות חשובות
task_logic – שבו יש את הבדיקה עצמה שמערכת הבדיקות קוראת לה ובה מועבר name ו-payload. פה אני קובע מה הלוגיקה
קריאה לLlmTaskResult עם תוצאות הבדיקה.
import logging
from openai import OpenAI
import os
from simpleval.consts import LOGGER_NAME
from simpleval.testcases.schemas.llm_task_result import LlmTaskResult
def task_logic(name: str, payload: dict) -> LlmTaskResult:
"""
Your llm task logic goes here.
You can (but you don't have to) use the simpleval logger which works with the verbose flag.
"""
print(
'NOTE: implement retries on rate limits. for bedrock, use `@bedrock_limits_retry` decorator (simpleval.utilities.retryables)'
)
logger = logging.getLogger(LOGGER_NAME)
logger.debug(
f'{__name__}: Running task logic for {name} with payload: {payload}')
your_prompt_for_the_llm = 'write a summary for this text.'
doc_name = payload.get("doc")
if not doc_name:
raise ValueError("Document name must be provided in the payload.")
else:
# Assuming the documents are stored in a 'docs' directory
file_path = os.path.join("docs", doc_name)
try:
with open(file_path, "r") as f:
content = f.read()
prompt = f'{your_prompt_for_the_llm}:{content}'
except FileNotFoundError:
raise FileNotFoundError(f"Document {doc_name} not found in path: {file_path}")
model_id = 'gpt-3.5-turbo'
# call to the llm with prompt and payload
client = OpenAI()
completion = client.chat.completions.create(
model=model_id,
messages=[
{"role": "user", "content": prompt}
]
)
llm_response = completion.choices[0].message.content
result = LlmTaskResult(
name=name,
prompt=your_prompt_for_the_llm,
prediction=llm_response,
payload=payload,
)
return result
הקריאה לLlmTaskResult עם התוצאות מכילה גם prompt – זה מאד מאד מאד חשוב. למה? כי זה מה שה-LLM as a judge מקבל. על בסיס זה הוא שופט את מה שה-LLM מייצר לנו.
ו… זהו. עכשיו צריך להריץ את זה עם uv run simpleval run. לא נשכח לעשות export OPENAI_API_KEY=YOUR_VALUE כי אחרת לא תהיה לנו ריצה – חייבים לשאול LLM כדי לבדוק אותו 🙂
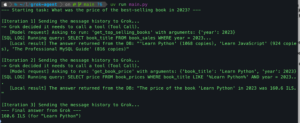
uv run simpleval run -e /Users/spare10/local/example_eval -t gpt35nanoכשאשר הפרמטר e- הוא המיקום של תיקית הפרויקט ו-t הוא שם התיקיה.
ו… ההרצה מתחילה, ראשית נשלחות כל השאילתות שלי ואז ה-LLM as a judge נכנס לפעולה ומתחיל לעבוד ולשפוט את כל התוצאות אל מול ה-ground truth. זהו!
הכל ירוץ ואז בסיום גם יפתח לי קובץ המציג את הבדיקה. אני אוכל לראות חלון שמבצע אגרגרציה על תוצאות הבדיקה או לבדוק כל בדיקה בנפרד כדי לראות מה השתבש.
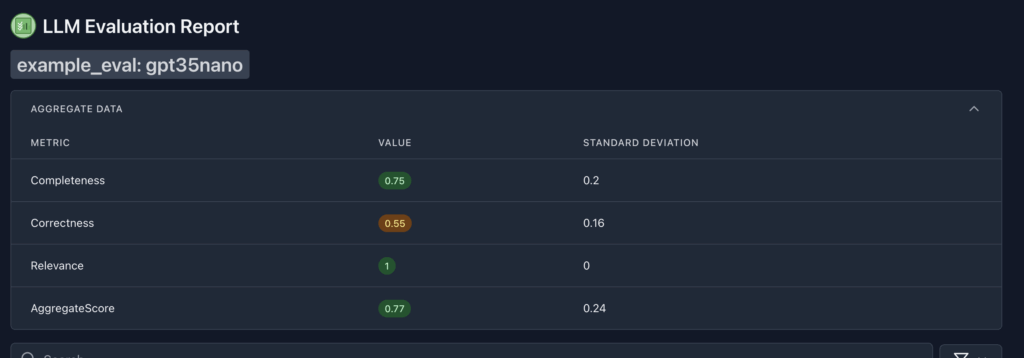
האם זה טוב או רע? ובכן… תלוי במה שאני מגדיר ומה שאני מצפה! במוצר, בהגדרות של מנהלי המוצר להצלחה או לכשלון וכו׳ וכו׳.
השוואה
אבל הכוח האמיתי של המערכת היא בהשוואה! בואו וננסה להריץ בדיקה נוספת ולהשוות בינהן. נכתוב בדיוק את אותו קוד בדיקה, אבל הפעם נשתמש במודל gpt-4.1-nano! זה ליטרלי אותו קוד – אבל עם שינוי קטן של ה-model_id, אבל אני ��ם אותו בתיקיה אחרת כמובן.
import logging
from openai import OpenAI
import os
from simpleval.consts import LOGGER_NAME
from simpleval.testcases.schemas.llm_task_result import LlmTaskResult
# @bedrock_limits_retry - use if using bedrock to call llm
def task_logic(name: str, payload: dict) -> LlmTaskResult:
"""
Your llm task logic goes here.
You can (but you don't have to) use the simpleval logger which works with the verbose flag.
"""
print(
'NOTE: implement retries on rate limits. for bedrock, use `@bedrock_limits_retry` decorator (simpleval.utilities.retryables)'
)
logger = logging.getLogger(LOGGER_NAME)
logger.debug(
f'{__name__}: Running task logic for {name} with payload: {payload}')
your_prompt_for_the_llm = 'write a summary for this text.'
doc_name = payload.get("doc")
if not doc_name:
raise ValueError("Document name must be provided in the payload.")
else:
# Assuming the documents are stored in a 'docs' directory
file_path = os.path.join("docs", doc_name)
try:
with open(file_path, "r") as f:
content = f.read()
prompt = f'{your_prompt_for_the_llm}:{content}'
except FileNotFoundError:
raise FileNotFoundError(f"Document {doc_name} not found in path: {file_path}")
model_id = 'gpt-4.1-nano'
# call to the llm with prompt and payload
client = OpenAI()
completion = client.chat.completions.create(
model=model_id,
messages=[
{"role": "user", "content": prompt}
]
)
llm_response = completion.choices[0].message.content
result = LlmTaskResult(
name=name,
prompt=your_prompt_for_the_llm,
prediction=llm_response,
payload=payload,
)
return result
אם העתקתם את התיקיה, שימו לב שאתם מעתיקים רק את הקוד ולא את התוצאות.
עכשיו נריץ שוב, הפעם עם שם התיקיה החדש gpt41-nano:
uv run simpleval run -e /Users/spare10/local/example_eval -t gpt41-nanoאחרי כמה שניות הכל ייגמר ונראה את התוצאות. אפשר לראות שיש שיפור משמעותי!
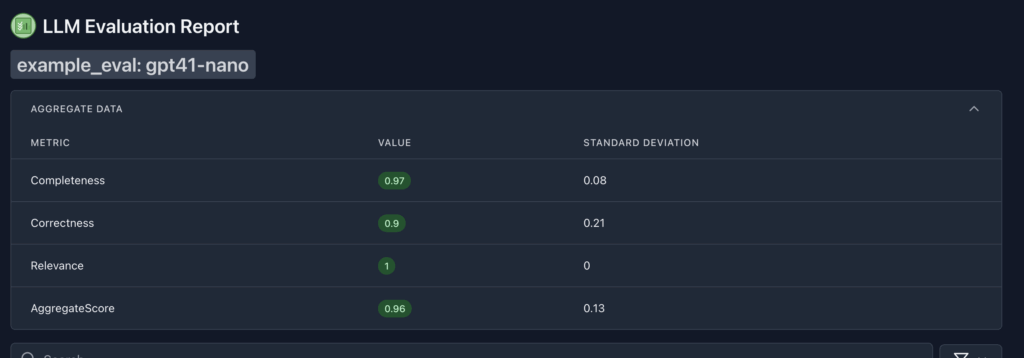
אני יכול להריץ גם בדיקה שתציג לי השוואה מסודרת! כל מה שאני צריך זה את שמות של שתי התיקיות ולהשוות בינהם. הבדיקה לא תרוץ שוב אלא תתבצע השוואה היסטורית.
uv run simpleval reports compare -e /Users/spare10/local/example_eval -t1 gpt4mini -t2 gpt4nanoוזו תהיה התוצאה:
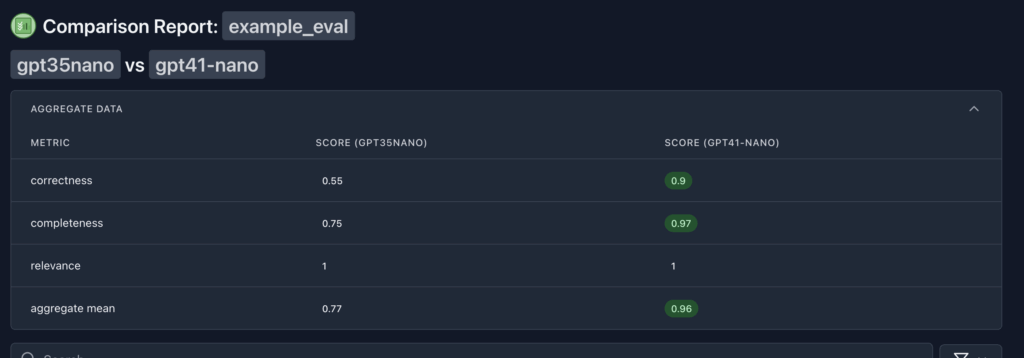
במה אבחר? שאלה מצוינת! אולי אני יכול לשנות קצת את הפרומפט כדי שיהיה יותר טוב וכך נוכל עדיין להביא תוצאות יותר טובות? מה הכשלים?
אני יכול להכנס לכל תוצאה ולבדוק מה ההסבר שהשופט שלי – כלומר ה-LLM as a Judge נתן לתוצאה. בממשק הגרפי. פשוט ללחוץ על הציון.
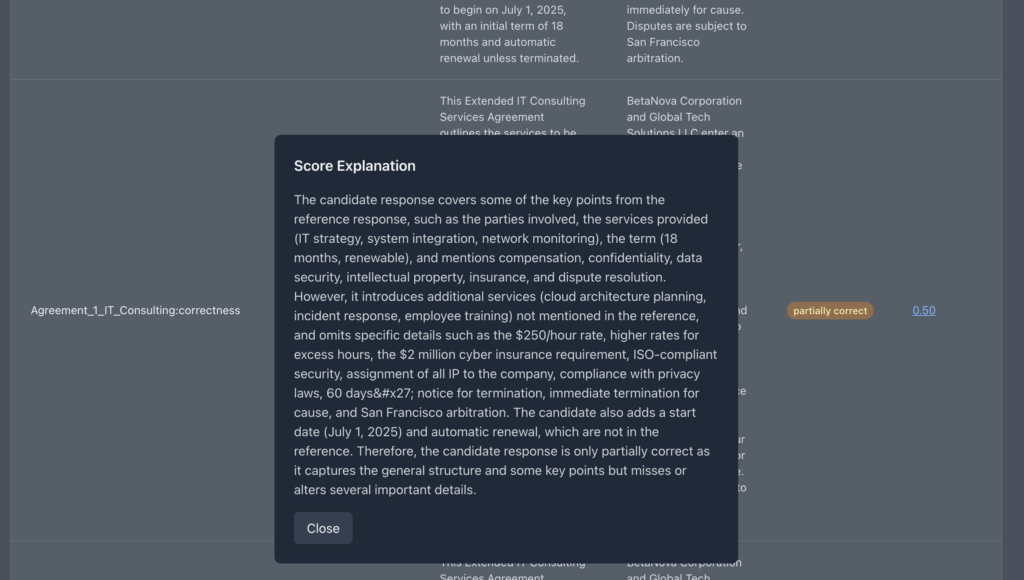
למשל ראיתי שיש בעיות של הזיות. אז אני יכול לשנות את השאילתה בהתאם.
למשל עם GPT3.5 שיניתי קצת את השאילתה:
Please write a summary for this legal agreement, be VERY PERCISE and make sure that you mention all the parties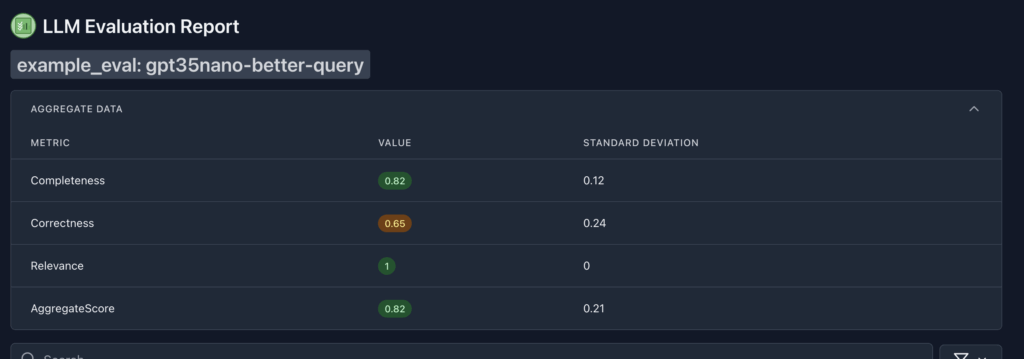
וקיבלתי תוצאות יותר טובות, לא משתוות ל-4.1, אבל טובות יותר ב-10 אחוז. אני יכול להמשיך ולשחק עם זה על אותו מודל, או להשוות למודלים אחרים – גם כאלו לא של OpenAI. מי שמממש את הקריאה זה אני, ואין בעיה לשים איזו קריאה שאני רוצה. לג׳מיני, ל-Azure, לקלוד. ווטאבר.
כל התוצאות נשמרות תחת תיקית results בפורמט html שאפשר לשלוח לכל אדם, גם לא טכני.
זה באמת פתרון מאד מוצלח ושימש אותנו היטב. אני ממש שמח שרועי בן יוסף הלך על האקסטרה מייל והצליח לשחרר את זה כקוד פתוח כדי שעוד אנשים יוכלו להנות מזה ואולי גם לתרום חזרה.
הערות
לפעמים ה-API זורק לי exceptions ומכשיל חלק מהקריאות בגלל Threshold, מה שצריך לעשות זה להריץ שוב את הקוד, רק מה שנכשל ירוץ שוב.
אם אני רוצה לעשות override ולמחוק את כל הקריאות (למשל להריץ את הבדיקה שוב), אז צריך להוסיף o- או למחוק את llm_task_results.jsonl ואת eval_results.jsonl מתיקית הבדיקות.
טיפ: אם אתם משנים שאילתות ובודקים שאילתות שונות, הקפידו שה-prompt שאתם שולחים ל-LlmTaskResult יהיה אותו דבר.
הכלי הוא כלי CLI אלטרנטיבי, כלומר אפשר תמיד להריץ uv run simpleval -h כדי לקבל מידע או uv rub simpleval COMMAND -h כדי לראות מה קורה וכמובן להעזר בדוקומנטציה הנרחבת שלו.