קיבלתי את הכבוד העצום והרב בלהיות המרצה הפותח בכנס OWASP AppsecIL. כנס המיועד לאנשי אבטחה המתמחים בפיתוח ובתהליכי פיתוח שמאורגן על ידי הסניף הישראלי של ארגון OWASP. בכנס דיברתי על איך מתקפה עתידית על LLM תראה כאשר התמקדתי פחות בטכני ויותר בקונספטואלי ובלנסות לנבא את העתיד, כאשר התזה שלי התמקדה בכך שאנחנו קצת לפני ההתפוצצות הגדולה של ה-LLM וההתקפות על LLM שכרגע אין יותר מדי מהן in the wild.
מה שאולי היה יותר מעניין הוא החלק בהרצאה בו דיברתי על התקפות על מודלים ��ל למידת מכונה לזיהוי תמונות. דיברתי על כמה התקפות כאלו ובפוסט הזה אני אתמקד בהתקפה של הוספת רעש לקלט של תמונה כדי למנוע ממודל של למידת מכונה לחזות בהצלחה מה יש בקלט הזה. בפועל זה אומר לשבש את מנגנון ה-Object Detection. הטכניקה הזו תוארה במאמר הזה. מי שמכיר את התחום ורוצה פחות חפירות ויותר קוד מוזמן לתת קפיצה מהירה למחברת הזו בגוגל colab ולהתחיל להריץ את הקוד. זה לא משהו חדש בכלל, אבל זה מאד מאד מעניין ואיכשהו עבר מתחת לרדאר של הרבה אנשים.
אז בגדול, איך מציאת אובייקטים עובדת? מודל ה-ML מקבל המון תמונות שבהן מסומן אובייקט מסוים. כאשר בתהליך האימון הוא ממיר את התמונה למספרים (מודל לא רואה כמונו) ומחפש דפוסים במספרים האלו ובונה פונקציה מתמטית שמשת לחיזוי. לא מדובר במשוואה פשוטה אלא במערכת מורכבת של מיליוני חישובים – אבל עדיין מדובר במערכת מתמטית. בתהליך האימון הוא משווה את התחזית שלו לתיוג הקיים. ובמידה והוא לא מצליח הוא משנה את הפונקציה המתמטית בדרכים שונות. בסופו של דבר המודל הוא פונקציה מתמטית.
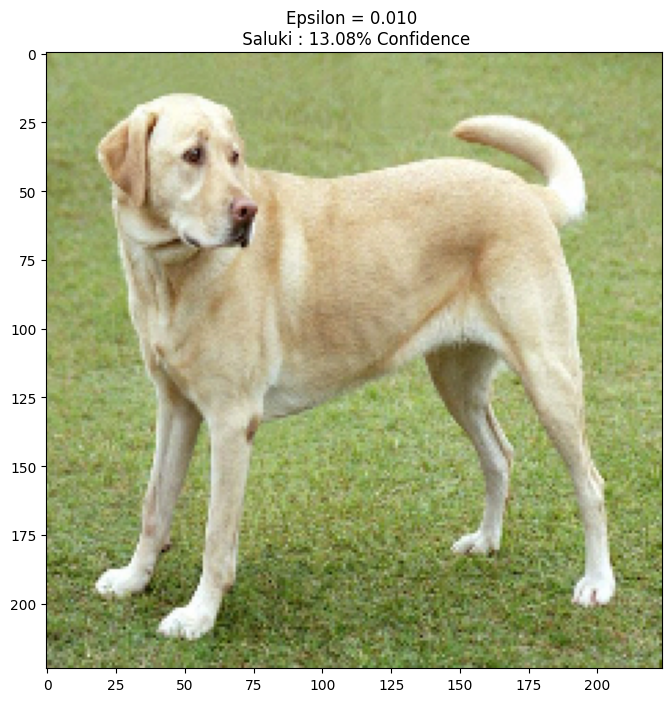
בואו ונסתכל על תמונה כזו למשל – של כלב (התמונה פתוחה לשימוש ברשיון GNU) אם אני אשלח אותה לרשת נוירונים מסוג MobileNetV2, היא תזהה את הכלב הזה.

הקוד שנועד להרצה הוא:
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} : {:.2f}% Confidence'.format(label, confidence*100))
plt.show()אם תריצו את הקוד תראו שהוא מצליח לחזות בדיוק של 42 אחוז את סוג הכלב החמוד.

איך אני יכול לשבש את היכולת של ה-ML לזהות את הכלב? אני יכול לייצר רעש ולהוסיף אותו לתמונה, הבעיה היא שעם מספיק רעש – התמונה לא תהיה מזוהה גם אצל בני אדם. אבל אני יכול להוסיך אלגוריתם מיוחד שנועד להוסיף רעש מצד אחד, אבל גם אמור ליצור תמונה שבני אדם ימשיכו לזהות וכך בעצם ה-ML יכול לזהות משהו שונה לגמרי ובני אדם שיסתכלו (בטח ובטח שבחטף) לא יבינו למה ה-ML נותן תוצאות שגויות (או יותר גרוע, פשוט יתעלמו). איך עושים את זה?
עם אלגוריתם רעש. למשל FGSM שזה ראשי תבות של Fast Gradient Sign Method – מדובר באלגוריתם שמוסיף רעש זעיר לקלט על ידי חישוב שקל להבין אותו אינטואיטיבית. ניקח את אוסף מספרים (כל פיקסל הוא מספר). ונשנה את הפיקסל הזה קצת למעלה או למטה כדי להשפיע על הטעות של האלגוריתם. אפשר לחשוב על זה כמוכמו מפה שמראה באיזה כיוון לשנות כל פיקסל כדי להפוך את התמונה ל"מבלבלת" עבור המודל. יש אלגוריתמים יותר מתוחכמים כמובן, אבל הוא יספיק לנו בשלב זה.
בגדול – מוסיפים רעש. ככה הפונקציה ליצירתו נראית. כדי להפיק את הרעש המקסימלי מבלי להפריע יותר מדי – צריך להעביר גם את התמונה עצמה וגם את התיוג שאנחנו רוצים להפריע לו:
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_gradיוצא משהו כזה:
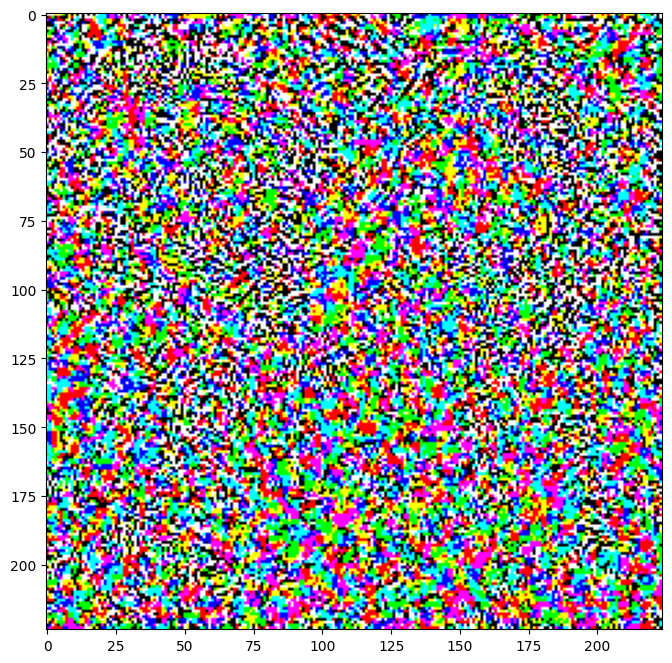
עכשיו מוסיפים את הרעש לתמונה האמיתית.
perturbations = create_adversarial_pattern(image, label)
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)ויוצאת תמונה, אם ניקח את התמונה ונסתכל עליה, נראה שיש רעש מאד מינורי. בקושי ניתן להבחנה. אדם יראה שמדובר בכלב לברדור. אבל עכשיו המכונה לא תבחין שמדובר בכלב לברדור. היא בקושי תזהה והזיהוי יהיה של כלב סלוקי.
כלב סלוקי הוא כלב ששונה מאד מאד מלברדור. הנה תמונה של סלוקי:

זה דמו קצר שמופיע במחברת שהבאתי לעיל. בקישור הזה יש דוגמה נוספת עם מחברת ותמונה של חתול. תרגישו חופשי לשחק עם תמונות נוספות.
סיכום ולמי זה אכפת
בגדול, ראינו טכניקה מאד מאד נחמדה ופשוטה להטעיית ML שמזהה תמונות. אדם יראה משהו אחד והמכונה תזהה משהו שונה לגמרי בגלל הטעיה. יש לזה משמעויות אבטחתיות במיוחד בעידן המולטי מודל – בינה מלאכותית שמשתמשת ב-ML לניתוחי תמונות. זו לא הטכניקה היחידה!
למה צריך להיות אכפת לנו? כרגע אין מתקפות in the wild שעושות שימוש בטכניקה הזו. זה יכול להשתנות. אבל, וזה יותר חשוב, אנחנו חייבים להפסיק לחשוב על קלט של תמונות כקלט שאי אפשר להכניס אליו payload זדוני. כמתכנתים התרגלנו כבר לחשוד בקלט טקסטואלי, אבל הגיע הזמן לחשוד גם בסוגי קלט אחרים שעוברים אל ML או LLM. מקווה שזה קצת פתח לכם את הראש.




{kind=link}
4 תגובות
איפשהו, הוספה של מעט איפור בלתי מורגש לסובבים, ומערכות זיהוי פנים לא ידעו לזהות אותך.
הוספה של כמה נמשים, פלולה, צללית בסנטר, החברים לא ירגישו, אבל הllm יראה מישהו אחר לחלוטין.
בצעד הבא, התחזות. בצורה הנ"ל, עם הוראות לזווית הנכונה לעמידה מול המצלמה.
בהצלחה
אתה מדבר על זיהוי פנים (Face recognition) ההתקפה הזו היא יותר על זיהוי אובייקטים. ולצערי איפור לא משנה מאד לאלגוריתמים החדשים של זיהוי פנים שמזהות גם על פי צילומים ישנים.
אולי רלוונטי להזכיר את המתקפות על תמרורים לצורך בלבול רכבים אוטונומיים (על ידי הוספת מדבקות שחור-לבן קטנות פה ושם). יש על זה מאמר יפה
https://arxiv.org/abs/1707.08945
Recent studies show that the state-of-the-art deep neural networks (DNNs) are vulnerable to adversarial examples, resulting from small-magnitude perturbations added to the input.
[…]
With a perturbation in the form of only black and white stickers,we attack a real stop sign, causing targeted misclassification in 100% of the images
רלוונטי מאד! תודה רבה!