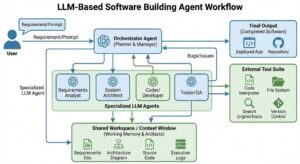
הטרנדים בתחום ה-LLM רבים כמו מגוון המנות בנאפיס ובאמת כבר קשה לעקוב. הטרנד החדש-ישן הנוכחי הוא שימוש ב-Agents. סוכנים – בגדול מודלים מסוימים שעושים כמה מטלות בשרשרת של פעולות ומחזירות את הקלט. למשל אם אני מעוניין ביצירת מידע של ״מה קורה במדינה X״ כדי להציג אותו בוידג׳ט, במקום ליצור בקשה אחת ל-LLM גדול ויקר כמו ChatGPT של ״מה קורה בצרפת״, אני יכול לשלוח בקשה לכמה LLMים. אחד שיבדוק מה מזג האוויר בצרפת, השני שיבדוק ויסכם את הכותרות ואחד שייצר תמונה מהתוצאות השונות ואז להציג שילוב של הכל בוידג׳ט. התוצאה תהיה הרבה יותר טובה מ-one shot שאנחנו ננסה לתפור עם שאילתה אחת ל-LLM.
יש המון פלטפורמות ליצירת AI Agents, אני למשל משתמש ב-AWS Bedrock. אבל יש עוד המון. מה שחשוב הוא להבין שלפעמים בשרשרת פעולות ארוכה יש לנו גם יכולות מדהימות להכשל או ליפול קורבן להזיות של המודלים השונים. במיוחד כשלא כל האייג׳נטים הם מודלים מהשורה הראשונה. ואז בונים מגדל מפואר של אייג׳נטים שעושים דברים, מקבלים מידע, שולחים מידע אבל מתרסקים כי י�� בהתחלה הזיה כלשהי שהולכת ומתנפחת.
או לחלופין – אנחנו צריכים הגנה שמתווספת ל Safeguard או ניטור נוסף של הפלט כדי לוודא שאין שם שמות של מתחרים או כל דבר חשוד אחר.
הפתרון הוא העברת הפלט של האייג׳נטים או של ה-LLM הראשי שלנו דרך LLM נוסף שכל תפקידו בעולם זה להעריך את הפלט. כשההערכה יכולה להיות כל דבר – מלבדוק אם התוצאה רלוונטית, לבדוק אם התוצאה זדונית או מכילה טקסט מסוים שאנחנו לא רוצים. כל מה שאנחנו רוצים בעצם לבדוק. אפשר גם לדרוש ציון מספרי ולפעול בהתאמה אליו.

בואו ונבדוק קוד לדוגמה. הקוד משתמש בפלטפורמה של AWS Bedrock אבל כתבתי אותו כך שהוא יהיה מובן. הקוד משתמש במודל nova-pro כדי לשאול שאלה ובמודל nova-lite, הזול הרבה יותר, כדי לבדוק את הפלט. מה שחשוב פה הוא הבנת הקונספט, לא ממש הקוד עצמו.
קודם כל הקוד, משתמשים ב-boto3 – הנה הוא למי שרוצה לקרוא אותו ישר. מי שרוצה פרשנות – אחרי הקוד:
import boto3
import json
# The main function, agent is getting a data
def fetch_product_prices_with_nova(query, bedrock_client, model_id):
# Define the system prompt for Nova
system_prompt = {
"text": "You are a knowledgeable assistant. Answer about the fruit prices: \n - Product: Apple, Price: $1. \n - Product: Orange, Price: $0.8. \n - Product: Banana, Price: $0.5. \nPlease provide more details based on the user's query."
}
# Define the conversation messages
messages = [
{
"role": "user",
"content": [
{"text": query}
]
}
]
# Prepare the request payload
body = json.dumps({
"schemaVersion": "messages-v1",
"system": [system_prompt],
"messages": messages,
"inferenceConfig": {
"max_new_tokens": 200,
"temperature": 0.7
}
})
# Invoke the Nova model
response = bedrock_client.invoke_model(
modelId=model_id,
body=body,
contentType='application/json',
accept='application/json'
)
# Parse the response
response_body = json.loads(response['body'].read())
return response_body.get('output', {}).get('message', {}).get('content', [{}])[0].get('text', 'No output generated')
# LLM as a judge function
def evaluate_with_nova_lite(prompt, output, bedrock_client, model_id):
"""
Evaluates the output using the Amazon Nova Lite model via Amazon Bedrock.
"""
# Define the system prompt
system_prompt = {
"text": "You are an AI model evaluator. Check if the output is about prices and products only. Provide a JSON object with an 'answer_score' (0-100) and a 'justification' for the score."
}
# Define the conversation messages
messages = [
{
"role": "user",
"content": [
{"text": f"User's prompt: {prompt}"}
]
},
{
"role": "assistant",
"content": [
{"text": f"Model's response: {output}"}
]
}
]
# Prepare the request payload
body = json.dumps({
"schemaVersion": "messages-v1",
"system": [system_prompt],
"messages": messages,
"inferenceConfig": {
"max_new_tokens": 1000,
"temperature": 0.5
}
})
# Invoke the Nova Lite model
response = bedrock_client.invoke_model(
modelId=model_id,
body=body,
contentType='application/json',
accept='application/json'
)
# Parse the response
response_body = json.loads(response['body'].read())
return response_body.get('output', {}).get('message', {}).get('content', [{}])[0].get('text', 'No output generated')
def main():
# Initialize Bedrock client
bedrock_client = boto3.client('bedrock-runtime', region_name='us-east-1')
# Model IDs for Nova and Nova Lite
nova_model_id = 'amazon.nova-pro-v1:0'
nova_lite_model_id = 'amazon.nova-lite-v1:0'
# Define the search query
query = "What are the prices of the yellow fruit? I forgot the name"
# Step 1: Fetch the data
try:
search_result = fetch_product_prices_with_nova(query, bedrock_client, nova_model_id)
except Exception as e:
print("Error during Nova search:", str(e))
return
# Step 2: Evaluate the search result using Nova Lite
try:
evaluation = evaluate_with_nova_lite(query, search_result, bedrock_client, nova_lite_model_id)
except Exception as e:
print("Error during Nova Lite evaluation:", str(e))
return
# Step 3: Print the results
print("Search Query:", query)
print("Search Result:", search_result)
print("Evaluation Result:", evaluation)
if __name__ == "__main__":
main()
מה הולך פה? אז יש לי פעולה מול LLM שהיא די פשוטה – אני מעביר לו שאילתה מהמשתמש (במקרה הזה מה-main אבל כמובן שזה רק קוד דוגמה), מעשיר אותו במידע נוסף – מחירים של פירות וירקות שעוברים דרך ה-system prompt. רק בשביל לפשט את הדוגמה.
איך אני יודע שבאמת ה-LLM השובב עשה את העבודה? אני לוקח את הפלט ומעביר אותו דרך nova-lite, מודל יותר זול ואז אני יכול לשאול אותו עד כמה הפלט תואם למה שאני מצפה לקבל ואף לתת ציון. במקרה הזה, אני פשוט מדפיס את הפלט.
הנה דוגמה לפלט שאני מצפה לקבל – הלקוח שואל מה המחיר של ״הפרי הצהוב״. ה-LLM המרכזי עונה וה-llm-as-a-judge נותן תשוב�� האם הפלט ולידי ונותן לו ציון. במקרה הזה 90:
Search Query: What are the prices of the yellow fruit? I forgot the name
Search Result: Certainly! Based on the provided prices, the yellow fruit you're referring to is likely the banana.
- **Product:** Banana
- **Price:** $0.5
If you had any other yellow fruits in mind or need more details, feel free to ask!
Evaluation Result: Here is the JSON object with the evaluation:
```json
{
"answer_score": 90,
"justification": "The response correctly identifies the yellow fruit as a banana and provides a price. However, it lacks additional details about other possible yellow fruits and could be more comprehensive."
}
```אבל אם השואל יתחכם, או שבאמת בשרשרת תהיה הזיה והשאלה תביא לאיזה פלט מוזר – השופט יוכל להכנס לסיפור. למשל, אם אני אשאל אותו אם ראש ממשלת ישראל הוא זקן? השאלה לא זדונית, לא מבקשים ליצור פה פצצה או להכין כל מיני חומרים. שאלה לגיטימית והתשובה גם לגיטימית. אבל זה בכלל לא קשור! אז במקרה הזה השופט יתן 0.
Search Query: Is the prime minister of Israel is old?
Search Result: The question about the prime minister of Israel's age is unrelated to the fruit prices you provided. However, I can give you information on the current Prime Minister of Israel and his age.
As of my last update, the Prime Minister of Israel is Benjamin Netanyahu. He was born on October 21, 1949, which makes him 74 years old as of 2023. Whether someone is considered "old" can be subjective, but at 74, Netanyahu is certainly in the later stages of life.
If you have any more questions about fruit prices or any other topic, feel free to ask!
Evaluation Result: ---
**Evaluation:**
```json
{
"answer_score": 0,
"justification": "The response does not address the user's question about the prime minister's age in a direct and relevant manner. Instead, it provides unrelated information about fruit prices and then answers the question about the prime minister's age, which is not the focus of the user's prompt."
}
```ההתנהגות והציון יכולים להכתיב את זרימת הקוד – לאן? זה תלוי בכם. אולי להדפיס ללוג והודעת שגיאה למשתמש, אולי להפעיל מחדש את השרשרת, אולי בדיקה אחרת. אבל אם אתם משתמשים ב-LLMים – צריך לזכור שהסיכוי שהם יטעו הוא גדול ככל שיש לנו שרשרת יותר גדולה.
כמובן שבכל הנושא של אבטחה, שילוב של LLM-as-a-judge יחד עם safeguard (והנה פוסט שלי על safeguard) מביא תוצאות מאד מאד טובות. כמה? ידידי ניב רבין שעובד איתי בסייברארק הביא לשיפור של 30 אחוז בפילטור של תוכן זדוני או בעייתי. גם דיברנו על זה בפודקאסט של עושים תוכנה שבו מדברים על הגנות.
אם המונח LLM as a judge היה עד עכשיו אבסטרקטי ולא מובן, אני מקווה שהקוד הזה – שאתם מוזמנים להריץ בכל רגע נתון, יסייע לכם להבין את הקונספט. כמובן שלא מעט פלטפורמות כבר מכניסות llm as a judge בלי שתצטרכו לממש אותו בקוד, אבל הקונספט חשוב להבנה פחות מהמימוש.