שנו רבותינו: בשביל כבוד אני צריך לרפרש את ה-cache! טוב, אולי לא רבותינו אלא להקת שב״ק ס׳ שהיום כבר מאד קרינג׳י להקשיב לשירים שלה. בגדול – כולנו יודעים ש-cache הוא נהדר לביצועים וגם גורם להזדקנות מוקדמת ולבאגים מוזרים. אבל הפעם נדבר על use case מאד מאד ספציפי: cache קטן וקצר מועד.

יש לנו לא מעט מקרים של שירות שמחזיר נתונים בכמות קטנה ובאופן צפוי שאפשר לומר שיש להם כ-15 דקות של גרייס. למשל – פרופיל משתמש. הפרטים המלאים של המשתמש נמצאים בדאטהבייס ולפעמים צריך אותם בשביל תצוגה ל-UI (למשל הצגת שם, שם תואר, כינוי, מדינה וכו׳), שירות משלוח מיילים, סמסים וכו׳). יש API שקורא למסד הנתונים. בד״כ הנתונים של המשתמש, בטח שהשם שלו, לא משתנים בתדירות של יותר מפעם ביום (במקרה הטוב) ויש גם שירותים שנועלים אפשרות לעדכון של יותר מפעם ביום. דוגמה נוספת? API שמחזיר את תחזית מזג האוויר בדיוק שעתי. תחזית מזג האוויר משתנה, אבל אולי לא בגרנולריות של יותר מ-15 דקה.
בד״כ עבור cache הדבר הראשון שאנו חושבים עליו הוא cache מבוסס מסד נתונים. Redis או משהו בסגנון. בעוד שזה פתרון מאד ולידי ומאד נכון בחלק גדול מהמקרים, כדאי לזכור שיש עוד פתרון אחד צנוע שנשכח לפעמים ועבור חלק מה-usecases הוא יכול להיות מעולה. מהו? in memory cache.
מה זה אומר? זה אומר שאת המידע שאנחנו מחזירים בקריאה הראשונה, אנו שומרים בזכרון ושולחים בקריאות הבאות לפרק זמן קצר. ככה בעצם מצליחים לחסוך בעלות ה-API ובקריאות למסד הנתונים, לקבל ביצועים טובים וכל זה עם קוד בלבד.
איך זה נראה באופן נאיבי?
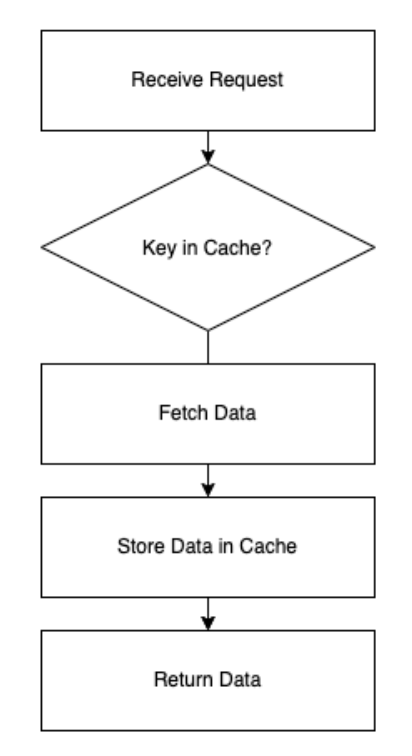
בואו ונמחיש עם קוד פייתוני שהוא מאד ברור גם למי שדובר שפה אחרת:
import json
cache = {}
def lambda_handler(event, context):
# Safely get the key from the event
key = event.get('key')
if not key:
return {
'statusCode': 400,
'body': json.dumps({
'error': 'No key provided in the request'
})
}
# Check if the key exists in the cache
if key in cache:
return {
'statusCode': 200,
'body': json.dumps({
'source': 'cache',
'data': cache[key]
})
}
# Simulate fetching data (could be a database or API call)
fetched_data = f"Data for {key}"
cache[key] = fetched_data # Save the fetched data in the cache
return {
'statusCode': 200,
'body': json.dumps({
'source': 'fetched',
'data': fetched_data
})
}
זה מימוש מאד פשוט אבל שיסביר בדיוק מה זה in memory cache. כל עוד הקוד רץ ופעיל, המשתנה cache שהוא בסקופ הגלובלי חי וקיים ובועט וברגע שמבצעים קריאה אחת, זו הקריאה האחרונה שנצטרך לבצע. הקריאות הבאות לא ילכו למסד נתונים או ל-API אלא ילכו ישר למשתנה ויחזירו ממנו מידע. זהו.
אבל רגע, מה הבעיה?
זה מימוש נאיבי, אז יש איתו טונות של בעיות. ראשית – אין שום ניהול של ה-cache. נגעת? נסעת. לצורך העניין אם הקוד ירוץ שנה, אין לנו יכולת לנקות את ה-cache או לבקש רענון שלא. כמו כן, יש מצב שהזכרון הפנימי יתמלא, אין לנו ניהול זכרון ובסופו של דבר אנחנו חיים במציאות של משאבים מוגבלים. זה עלול להיות באמת בלגן ובגלל זה הקוד שלעיל הוא קוד דוגמה להמחשה. לא משהו שאתם רוצים להשתמש בו. בגלל זה עדיף לנו להשתמש בספריה שתנהל את הכל. אחת כזו היא least-recently-used – LRU. זה מונח שמשמעותו היא ״זה שהשתמשו בו אחרון״ וכשמו כן הוא – מערכת לניהול cache פנימי מסודרת ופשוטה שמגדירה גודל של זכרון ומחליפה את הישן בחדש. כך אנו שומרים גם על עדכנות של ה-cache, גם נמנעים מהצפה של הזכרון וגם נהנים מיכולות לנהל את הקוד.
בכל שפה יש אימפלמנטציה של lru cache. בפייתון היא קיימת מגרסה 3.2 של השפה כמודול מובנה. קל מאד להשתמש בה עם דקורטור. בקוד הזה למשל, שייצרתי עם ChatGPT לאחר הנחיות מדויקות, יש לנו הדגמת שימוש באמצעות שימוש ב-API של בדיחות אבא. את ה-lru cache אני מפעיל באמצעות דקורטור עם שורה אחת שבה אני מגדיר את גודל ה-cache ו… זהו! מהנקודה הזו, כל עוד הקוד רץ, יהיו ב-cache עשר תוצאות. אם תריצו את הקוד הזה, תראו שקריאת ה-API הראשונה יצאה, אבל השניה לא תצא כי היא תשמר ב-cache.
import requests
from functools import lru_cache
@lru_cache(maxsize=10) # Cache up to 10 API responses
def fetch_dad_joke(joke_id=None):
headers = {"Accept": "application/json"}
if joke_id:
url = f"https://icanhazdadjoke.com/j/{joke_id}"
else:
url = "https://icanhazdadjoke.com/"
print(f"Fetching joke from {url}...")
response = requests.get(url, headers=headers)
response.raise_for_status()
return response.json() # Return the joke as JSON
if __name__ == "__main__":
print("Fetch joke by ID:")
print(fetch_dad_joke("08xHQCdx5Ed"))
print("Repeat same ID joke:")
print(fetch_dad_joke("08xHQCdx5Ed"))
# Display cache info
print("\nCache Info:")
print(fetch_dad_joke.cache_info())
בפייתון זה מאד נוח להשתמש בזה. גם ב-Node.js יש כמה מודולים או שאפשר לממש את זה לבד (לא מומלץ).
למה חשוב להכיר דברים כאלו?
בעבר אם לא ידעתם שיש כזה דבר, אז הייתם בבעיה חמורה. היום יש לכאורה קופיילוט ו-ChatGPT שיכתבו את זה עבורכם. אבל (!) כשאנחנו מתכננים את מערכת הקוד שלנו אנחנו צריכים להורות לבינה המלאכותית להשתמש בפתרונות כאלו ולחשוב עליהם מראש. זה התפקיד של המתכנת או המתכנתת בעידן החדש הזה – להכיר מבנים של תוכנה, להבין איפה ואיך הסביבה עובדת ואז להורות לבינה המלאכותית לעבוד בהתאם.
הבינה המלאכותית לא יכולה לדעת שהקריאות של הלמבדה שלכם למשל מתאימות ל-lru cache, רק אתם יכולים לדעת כי אתם מבינים את הקונטקסט המלא. אם תבקשו cache, יש מצב שתקבלו המלצה להשתמש ברדיס או שירות cache חיצוני. הבינה המלאכותית יודעת לייצר קוד (יותר נכון טקסט) אבל היא לא מבינה את ההקשר של הקוד שלכם ואיפה הוא עובד.
זה לא אומר כמובן ש-lru cache מתאים תמיד להכל ובכל מקום. הוא כלי ספציפי לבעיה ספציפית (כשצריך cache זמני, קטן, לא יקר). ברוב הפעמים לא תצטרכו אותו אלא שימוש ב-cache מבוסס מסד נתונים. אבל כאמור – כדאי להכיר!
ומי שהגיע עד לכאן – בונוס – הרצאונת קצרצרה שלי ב DevopsdaysTLV 2024 על העניין הזה





2 תגובות
הרגת אותי עם האנגלית שלך
מי היה המורה שלך? מיסטר גרנד מייזיר?
ועכשיו ברצינות:
היה אחלה
כתבה מעולה
זה פתרון למערכת שלא בנויה לסקייל רק נכון?
בנוסף אשמח מאוד אם תפרסם בטלגרם ערוצים שבהם אתה מתעדכן טכנולוגיה ובעיקר פיתוח 🙂