כדי לסייע לסטודנטים שאני מלמד במקומות שונים ואיכשהו תמיד חסרים לי מאמרים שאני יכול לשלוח לסטודנטים המסבירים למי שלומד מדעי המחשב דברים בסיסיים באבטחת מידע ובעברית. יש לא מעט מאמרים (אשתדל לתת קישורים איפה שיש) עם הסברים אבל ההסברים מיועדים לאנשים שלומדים אבטחת מידע ומכילים כבר מונחים מהתחום שפחות רלוונטיים לאנשים שצריכים ללמוד את המבוא. אז כדי לעזור לעצמי, כתבתי סדרת מאמרים שמסבירים מונחים בסיסיים באבטחת מידע ובדגש על ווב ופיתוח ומה שמפתחים מתחילים צריכים לדעת. במאמר זה אני מסביר על התקפה מעניינת ונפוצה בשם גוגל דורקינג.
יש בעיה משמעותית מאד עם גוגל ובכלל עם מנועי חיפוש – הוא סורק כל מקום שהוא יכול להגיע אליו. מנועי חיפוש עובדים בגדול באופן כזה: הם נכנסים לדף, סורקים את תוכנו ושומרים אותו או מילות מפתח הקשורות אליו ואז קוראים מייד את כל הקישורים שיש בו ונכנסים אליהם וכך הלאה. גם קישורים שלא תמיד רוצים או מעונינים שיופיעו. יש אתרים המכילים מפת אתר – שזו רשימה של תוכן שיש בדף שנועדו לסייע למנוע החיפוש למצוא את הדפים בקלות רבה יותר (גם בבלוג שלי יש מפת אתר) ולפעמים נכנסים לשם קישורים לא לעניין.
מי שרוצה לשמוע איך זה יכול ממש להזיק, יכול להאזין לפרק הזה שהקלטתי בזמנו בחיות כיס ובו מתואר מקרה מבאס כזה שאירע למישהו תמים לגמרי שסריקה לא נכונה של גוגל החריבה את שמו הטוב. אני מספר שם איך מנוע חיפוש עובד.
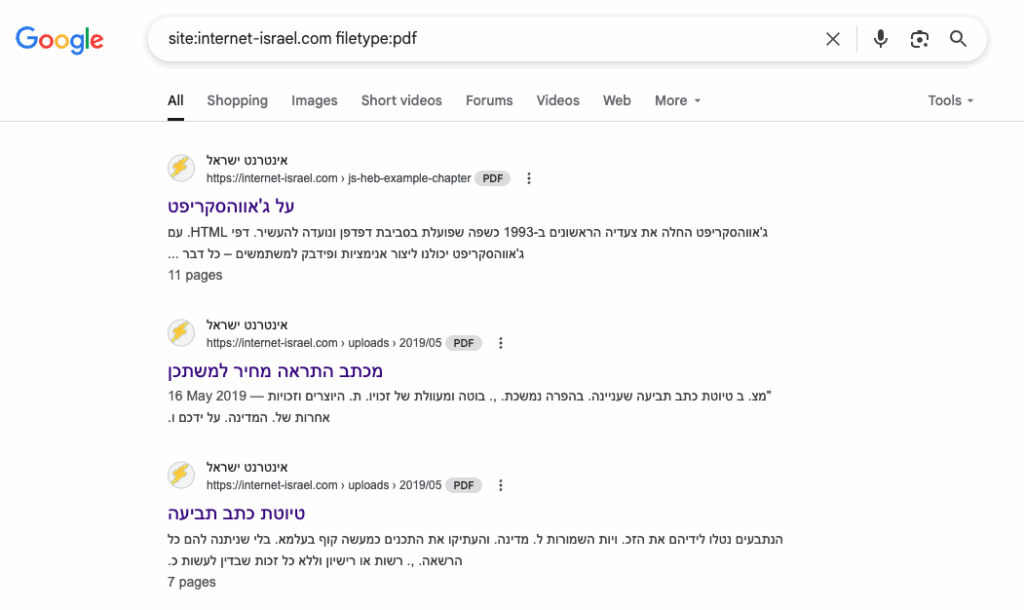
הטכניקה גוגל דורקינג ובאנגלית Google Dorking היא בעצם שימוש בגוגל על מנת למצוא מידע שבעלי האתר לא רוצים שתמצאו. בבסיס גוגל דורקינג עומדות טכניקות שונות למציאת דפים וקבצים שונים באתרים. הטכניקות האלו מאפשרות למשל למצוא את כל קבצי ה-PDF של אתר מסוים. למשל, אם תכניסו בגוגל את הטקסט הזה:
site:internet-israel.com filetype:pdfאתם תמצאו את כל קבצי ה-PDF שיש לי באתר. את כולם העליתי וכולם, באופן עקרוני, אמורים להיות מותרים לפרסום ואין בעיה אית��. אבל… מה אם העליתי את זה במסגרת פוסט והתחרטתי ומחקתי את הפוסט? הקובץ יישאר ויש מצב שאם גוגל סרקה את הפוסט המקורי, היא יודעת מה המיקום של ה-PDF ותציג אותו בתוצאות החיפוש. מה אם חשפתי בטעות ממשק סודי שיש בו קבצים שלא אמורים להיות שם? אז מי שיחפש קבצי PDF באתר שלי יופתע לגלות קבצים שהוא לא אמור לראות!
אפשר כמובן לחפש דברים אחרים ולא רק באתרים ממוקדים – למשל
filetype:pdf קורות חיים תעודת זהותוהוא יביא לכם שלל של קורות חיים בפורמט PDF שיש בהם מספרי תעודת זהות.
יש לא מעט פילטרים, סיור מהיר בצ׳אט של בינה מלאכותית יתן לכם את זה, אבל אני שם אותו פה לטעימה:
| פילטר | תיאור | דוגמה |
|---|---|---|
site: | חיפוש בתוך דומיין מסוים בלבד | site:gov.il |
inurl: | חיפוש במחרוזת ה-URL של הדף | inurl:admin |
intitle: | חיפוש בכותרת העמוד | s |
filetype: | חיפוש קבצים לפי סוג מסוים | filetype:pdf |
ext: | כמו filetype:, אבל פחות נפוץ | ext:docx |
intext: | חיפוש בטקסט המלא של הדף | intext:"סיסמה" |
cache: | הצגת הגרסה השמורה של דף אינטרנט | cache:example.com |
related: | מציאת אתרים דומים לאתר נתון | related:example.com |
link: | חיפוש דפים המקשרים לדף מסוים | link:example.com |
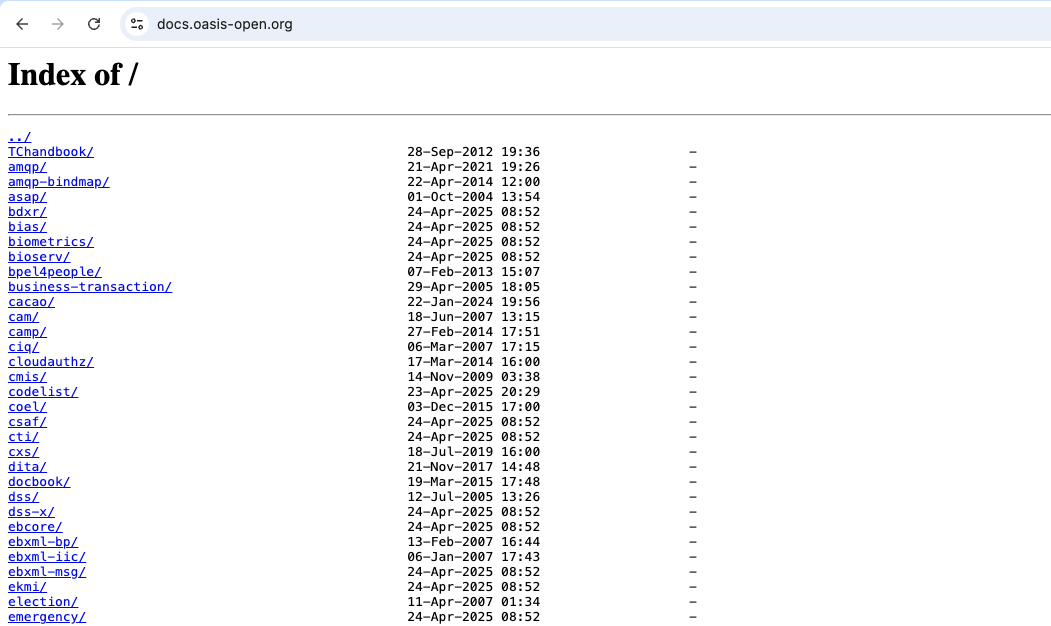
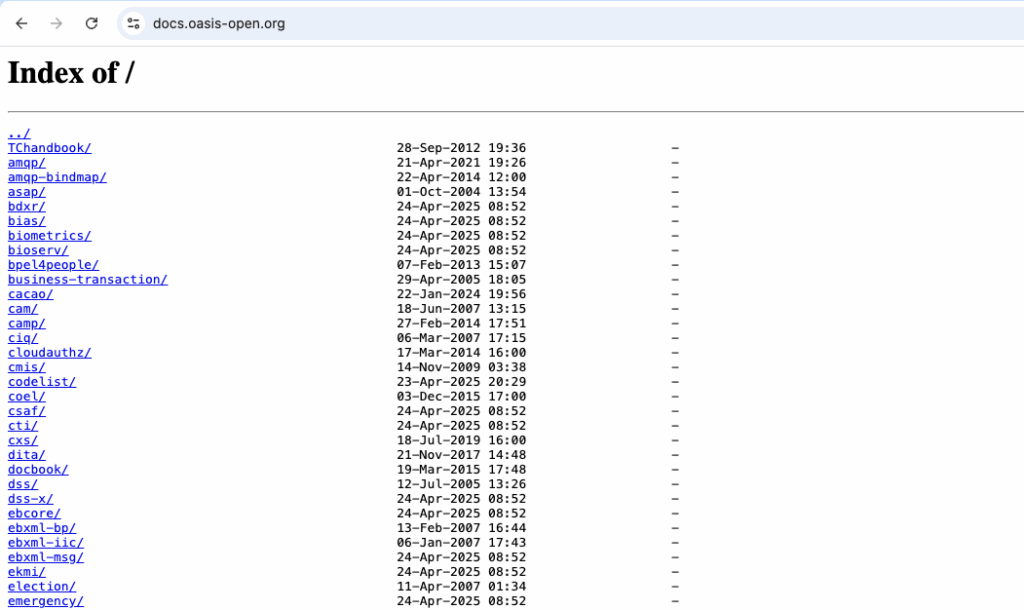
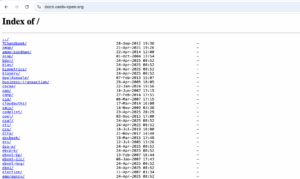
Index of
אחד מהדברים המלהיבים ביותר שיש בגוגל דורקינג הוא index of, יש תכונה בשרתים מסוימים להצגת כל הקבצים בדיוק כמו סייר קבצים.
אני אסביר מה זה שרתי אינטרנט. שרתים הם בעצם מחשבים שמחוברים לרשת. מחשבים שבאופן עקרוני לא שונים מלפטופ או מחשב שולחני. מותקנת עליהם מערכת הפעלה (לינוקס או חלונות) ובמערכת ההפעלה הזו מותקנת תוכנה שנקראת ״שרת״. התוכנה הזו יודעת לעבוד עם דפדפנים. כך למשל, אם יש לי מחשב ואני מחבר אותו לרשת ומקבל כתובת IP של 6.38.20.20, אם אני מתקין עליו שרת, השרת ידע להציג דפים למי שמכניס את הכתובת 6.38.20.20 לדפדפן, או שם מתחם הקשור אל 6.38.20.20. הדפים שהשרת מציג יכולים להיות דינמיים או קבצים על השרת כולל תמונות, קבצי קוד, סרטונים, קבצי קול וכו׳ וכו׳. הקבצים האלו הם בדיוק כמו הקבצים שיושבים אצלכם.
חלק מהשרתים מכילים ��כונת ברירת מחדל שמציגה את כל הקבצים שיש על השרת במבנה תיקיות מסודר. זו תכונה שמקלה על המתכנתים ובוני האתרים שמשתמשים בשרת כל עוד עובדים עליו והוא מחובר לרשת הפנימית, אבל כמובן שזה רעיון רע מאד לעשות בשרת שחשוף לאינטרנט. רע מאד. איך מוצאים שרתים שהמפעילים שלהם שכחו לכבות את האפשרות הזו? ובכן:
intitle:"index of" site:ilתגלו המון אתרים ישראלים שמציגים רשימה של הקבצים שלהם. הרוב המוחץ של הקבצים הוא בסדר גמור – תמונות שאמורות להיות באתר, סרטונים שאין איתם שום בעיה וכו׳ וכו׳. אבל חלק אחר? לכו תדעו…
מניעה
למעט ההמלצה לוודא שיש Access Control מסודר על קבצים שאנחנו לא רוצים שידלפו – אין המלצה נוספת. פשוט בנייה נכונה וניהול נכון של משאבים.
פריצות שהיו
היו מלא דלפי מידע שהתגלו בגוגל דורקינג. המונים. למשל מקרה שבו נחשפו המון חשבונות ארנונה כתוצאה מחיפוש בבינג. מידע שדלף מאתר לממכר קנביס הכולל מידע רפואי מאד רגיש. מידע רפואי על טירונים בבא״ח גבעתי ו… וואו, היו עוד המון.


8 תגובות
האם זה נחשב פריצה ? והאם זה חוקי?
למיטב ידיעתי זה חוקי, השתמשת בקישור מגוגל
אני לא יודע מה הסטטוס של השטות הבאה, אולי הבינו כבר שזה מטפוש
בכל אופן
אסור לשנות בקישור כלום, אפילו לא רווח
אז הדפדפן באמת הופך לכלי פריצה
הלוגיקה היא נסיון (מטופש) היא למנוע מאדם לתקן ID של קישור שקיבלת ולקבל מיידע של מישהו אחר.
לא חושב שהבנת את הכתבה. מה זה ID של אתר? התכוונת לIP או לשורת הURL?? לא התנסחת ברור…
דורקינג זה לא 'לשנות' URL (אין כזה דבר "לשנות" לאתר את הURL שלו אא"כ אתה בתוך הקבצי מנהל עם הרשאת מנהל שזה פריצה קלאסית לשרת וממש לא דורקינג = השגת מידע רגיש)
גם השורה האחרונה שכתבת בתגובה נראית כאילו כתבת אותה מתוך שינה כי אין לה שום מובן
לא, זה לא חוקי למרות שכלפי חוץ זה נראה חיפוש תמים! אבל כמובן שלעולם לא יעשו לכם כלום על זה (גם אם תתעדו את עצמכם עושים גוגל דורקינג) כמו הרבה 'עבירות קלות' במדינת ישראל
אסור לאסוף מידע על אנשים במדינה וכולל גם דורקינג
תופעה מעניינת, אבל לא הבנתי כל כך איך משתמשים בה ולמה היא מועילה יותר משיטוט באתר.. אני יכול לעבור על כל קבצי ה-pdf באתר בדיוק כמו שאני יכול לשוטט בפוסטים מאוד ישנים ומוזנחים שעלולים לכלול מידע יותר אישי
כי אין קישור מהאתר עצמו
בגוגל דורקינג תמצא מידע שלא תוכל למצוא לעולם בחיפוש הקלאסי של "שיטוט באינטרנט"!!! ואני עומד מאחורי מה שאני אומר כיוון שנתקלתי בזה עשרות פעמים!!! ואגב, הדוגמא הראשונה שהוא הביא של דליפת הגשות להנחה בארנונה באמצעות חברת "מאסט" זה דליפה שראיתי בעצמי במו עיני והדליפות האלו נפוצות מאוד (אנשי האוסינט מחפשים מידע גלוי על חברות/אנשים/מדינות/ארגוני טרור גם באמצעות ה"גוגל דורקינג" ואי אפשר להאמין לפעמים לאיזה מכרות זהב הגיעו…
אני סטודנט חדש יחסית בתחום ולא מבין
הקישורים לקבצים יושבים בdb והשרת מחזיר אותם רק בתגובה לבקשה ספציפית אז איך גוגל יכןל לראות את הקבצים של האתר?