במאמר הקודם למדנו על git pull שמסייע לנו לייבא את כל השינויים מהענף המרוחק אלינו. למשל, אם יצרנו ענף כלשהו מענף develop, פיתחנו ופיתחנו על הענף שלנו ועכשיו אנחנו רוצים למזג אותו חזרה ל-develop. איך עושים את זה? ראשית מוודאים של-develop לא יהיו קונפליקטים איתנו (אם למשל מפתח אחר דחף שינויים ל-develop על אותם קבצים שאנחנו נגענו בהם). אין מוודאים? עושים pull (שעושה אוטומטית merge) עם הענף שאליו אנחנו רוצים להתמזג.
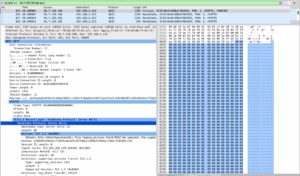
מה קורה בעצם? קורה התהליך הבא:
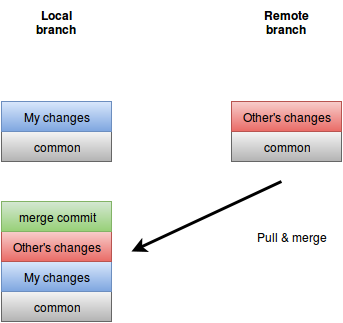
תהליך ה-pull לוקח את השינויים שנעשו בשרת המרוחק, מכניס אותם לשרת שלי ויוצר merge. גם אם אין קונפליקטים וזה חשוב מאוד. אם יש קונפליקטים, אני צריך לעשות להם resolve, לדחוף את השינויים חזרה לענף המקומי שלי ואז ליצור pull request.
זה טוב ויפה, אבל הבעיה היא שאם עובדים בצוות גדול, בגלל כל ה-merge המיותרים, הלוג של הגיט מתלכלך בהמון הודעות merge מיותרות. על מנת להמנע מכך, יש לנו פרקטיקה שונה במקצת של merge שנקראת rebase. איך git rebase עובד? באופן פשוט – קודם הוא עושה רולבק לכל השינויים שעשיתי בגרסה המקומית. הולך לגרסה שאני רוצה להתמזג אליה, ומתחיל לדחוף את כל השינויים שחלו בה לפי הזמן, אחד אחרי השני, כאשר הוא נתקל בקומיט שלי הוא מוסיף אותו על כל השינויים. אם יש לי כמה קומיטים, הוא מוסיף אותם לפי הזמן שבו הם נכנסו. כלומר הוא עושה 'הדמיה' כאילו דחפתי את הקוד שלי אחרי כל שינוי.
איך זה נראה? ככה:
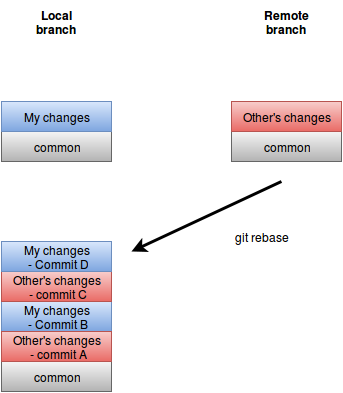
כלומר, ה-rebase עושה רולבק עד לנקודת הזמן שבו היה הפיצול. לוקח את הקומיט הראשון לפי תאריך ושם אותו. לוקח את הקומיט השני ושם אותו על הראשון וכך הלאה עד שמסיימים. אם יש קונפליקט, התהליך עוצר ונדרש מהמשתמש ליישב את הקונפליקט ורק אז להמשיך בתהליך. רק אחרי שכל הקומיטים – המרוחקים והנוכחיים הסתיימו, רק אז ה-rebase מושלם ואפשר לפתוח Pull request.
מבחינה טכנית עושים את זה ככה:
git rebase origin develop
ובמידה ויש קונפליקט, יש ליישב אותו ואז:
git rebase --continue
אם נמאס לכם ואתם רוצים לחזור למצב שלפני שהתחלתם לעשות rebase, אז:
git rebase --abort
אחרי שהכל תקין, עושים קומיט עם כל השינויים ואז פותחים pull request.
מתי משתמשים ב-rebase?
התהליך של rebase נראה קצת מבלבל וגם קצת מבהיל ברגע שמבינים שהתהליך בעצם כולל rollback של השינויים והצבה שלהם מחדש לפי סדר כרונולוגי על גבי קומיטים שנעשו בשרת המרוחק. אבל מאוד כדאי לעשות את זה כי אם נעשה pull בכל פעם, במיוחד בצוות גדול, אז הלוג יהיה מאוד מלוכלך.
מתי לא משתמשים ב-rebase?
מאוד כדאי להמנע מ-rebase על ענפים שיש לאנשים אחרים גישה אליהם. מה זאת אומרת? אם זה על הענף המקומי שלי שרק אני עובד עליו – מעולה. אבל אם זה ענפים שעוד אנשים עובדים עליהם, rebase עלול לגרום לבעיות כיוון שהוא משנה בפועל את ההיסטוריה של הענף. אם יש עוד מישהו שעובד על הענף הזה, העובדה ששיניתי את ההיסטוריה שלו יכולה להרוס לו את העבודה ולהכניס אותו לקונפליקטים בלתי נגמרים.
במאמר הבא אנחנו נראה דוגמה בפועל של שימוש בגיט בקוד אמיתי. stay tuned!


7 תגובות
מעולה.
הסברים טובים ביותר.
כמו כן למי שרוצה לדעת קצת יותר בGIT2.7 ישנה אפשרות חדשה:
git rebase –no-autostash
מאפשר להשתמש בrebase בלי להכניס את הקוד לתוך stash לפני הrebase
מעולה! טוב לדעת ותודה על מה שכתבת!
תודה, מאמרים טובים.
לא הבנתי אבל למה בסוף כל זה צריך לעשות PULL, מה הוא יחדש לי?
המון תודה!
הכוונה היא לפתיחת pull request. פתיחת ה-pull request מאפשרת לי למזג את הקוד שלי אל הענף המרכזי. את זה אני יכול לעשות אחרי ה-rebase כי לא יהיו לי קונפליקטים.
לא הבנתי, רשמת בתחילת העמוד שיש בעייה לעבוד עם git pull כאשר יש הרבה חברי צוות כי הלוג מתלכלך, ולכן יש פרקטיקה שונה של merge שנקרא rebase. וגם הראת רק דוגמאות של rebase מול ענפים במאגר מרוחק. ואז בסוף הכתבה רשמת שמאוד כדאי להמנע מ-rebase על ענפים שיש לאנשים אחרים גישה אליהם. אז אני לא מצליח להבין. כי יש פה סטירה במה שאמרת בהתחלה למה שאמרת בסוף. ועשיתי ניסיון פתחתי 2 ענפים אצלי במחשב, ובכל אחד מהם עשיתי כמה commits בסדר כרונולוגי ככה שפעם אני בענף הראשון ופעם בענף השני. אבל אז כשעשיתי rebase הוא לקח את כל ה-commit של הענף הראשון שם אותם בהתחלה ורק בסופם שם את ה-commits של הענף השני. זה לא מה שהראת בדוגמא. בבקשה עזרה להבין את זה.
אני אנסה להסביר יותר טוב – ראשית rebase רלוונטי במיוחד למקרים שיש בהם ענף מרוחק שאתה צריך להסתנכרן מולו. מה הוא עושה? בגדול לוקח את כל הקומיטים שלך, את כל הקומיטים של האחרים לענף המרוחק ושם אותם בסדר כרונולוגי אחד אחרי השני. אם יש קונפליקטים אתה צריך לפתור אותם ברגע שהם מופיעים ואז להמשיך בתהליך שמושלם רק כשכל הקומיטים – שלך ושל הענף המרוחק ��ערמים אחד על השני.
מתי אסור לעשות rebase, כאשר אתה עושה rebase לענף במחשב שלך שמישהו אחר גם משתמש בו.
למשל, נניח שיש לי ענף בשם release-1 והוא יצא מ-master, אם אני עושה לו git rebase master, אז הוא לוקח את כל הקומיטים שנעשו ל-master, את כל הקומיטים שאני עשיתי ל release 1 ומסדר אותם לפי סדר כרונולוגי. אם מישהו אחר משתמש ב release-1 (למשל עשיתי לו push ומישהו אחר משתמש בו, וזה לא משהו לא נפוץ) – עדיף לא לעשות rebase אלא merge.
הסברים מעולים שממש עוזרים. תודה!