עם העולם החדש של למידת המכונה, הבינה המלאכותית ושאר קללות ה-AI – יש יותר ויותר זליגה של עולם הדאטה סיינס (באנגלית Data Science) אל עולם המתכנתים ומונחים כמו dataframe ושימוש במחברות ובפנדה כבר הפכו להיות יותר נפוצים בקרב מתכנתים. בעבודה יוצא לי לא מעט לעסוק בתכנים כאלו אבל אפשר לרתום את כוח ה-ML גם לעולם המדהים של ה-IoT -חיישנים ומיקרובקרים שיכולים להפעיל בית חכם או להפעיל כמה תעלולים. שילוב של AI ו-IoT נקרא AIoT ועסקתי בו לא מעט.. בפוסט הזה אנו נלמד איך יוצרים ובודקים מודל tflite כדי לבדוק אנומליות של חיישן גזים. נלמד על מה זה דאטהסט, מה זה דאטהסט סינתטי, איך מכינים דאטהסט מהסוג שלנו לאימון, אימון ובדיקה ואז דיפלוט ל tflow lite. בפוסט הבא נלמד איך מדפלטים אותו למיקרובקר מסוג esp32. הנימה פה היא מאד משועשעת ובסופו של דבר אנחנו מדברים על חיישן פלוצים, אבל בתהליך אפשר ללמוד המון.
הפוסט הקודם בסדרה מסביר איך לחבר חיישן מתאן MQ4 אל ESP32 – אנחנו נצטרך את המידע הזה מאוחר יותר.
מה הולכים לעשות?
חיישנים מבצעים קריאה של הסביבה והמרת הנתון למספר שאפשר לעבוד איתו. את החיישן אפשר לחבר לרספברי פיי או ל-ESP32 ואז להפעיל פעולות שונות. למשל – חיישן מתאן (שזה בגדול גז שיוצא ב… נו, איך לומר את זה, פלוצים) יכול להתריע מעל סף מסוים. למשל – להדליק נורת אזהרה כשהשירותים מצחינים (הערך של החיישן הוא מעל 4000 למשל). זה עמוק בתוך ה-IoT וקל ופשוט לעשות את זה וראינו בפוסט הקודם איך לעשות את זה.
זיהוי אנומליה אל מול חציית סף
עולם ה-ML מאפשר לי לחזות בלגן בשירותים לא רק לפי חציית סף, לפי זיהוי אנומליות. זיהוי אנומליות זה תחום שלם בהסתברות ויש כמה גישות, אנחנו נלך על גישה נאיבית. נסתכל על סדרה של קריאות של חיישן מתאן ונשווה אותן לסדרות אחרות באותו גודל. אם אנחנו ��ואים שהסדרה הנוכחית לא ניתנת לניבוי ויש סטייה בינה לבין סדרות דומות – סימן שהולך להיות בלגן בשירותים ואנחנו יכולים לתת התראה עוד לפני שיש את חציית הסף או את ה Threshold. כך המבקר בשירותים יכול לנקוט אמצעי נגד כמו הדחת המים, הפעלת מטהר אוויר או זעקות אזהרה לאלו שמחכים בחוץ גם מבלי שהוא חוצה סף של סרחון.
יותר מזה – אנחנו יכולים לעלות ככה על מי שמשחרר לו גזים בהנאה בחדר שלנו (או בקיוביקל!). זה ממש קלאסי ל-anomaly detection כיוון שבניגוד ל-Threshold שקל להפעיל בשירותים, לא מעט פעמים הסרחון בחלל החדר הוא יותר חמקמק. אין לי איזו קפיצה משוגעת של גז מתאן שיעבור את הסף ויקפיץ אזהרה אלא קפיצה הדרגתית או שינוי הדרגתי שלא חוצה סף מסוים למטה או למעלה – למשל מישהו שמתאפק לפני ההפגזה ואז רואים ירידה או מישהו שמנסה להוריד את מפלץ הלחץ עם שחרורים קטנים. אז פה זה קלאסי – נוכל לעלות על המסריח לפני שיש חציה של סף. חשוב להבין את הסיבה לשימוש ב-ML כי הרבה מאד פתרונות לגילוי הסרחה שמדברים עליהם הם מבוססי סף – כלומר חיישן המתאן עבר סף, קיבלנו התראה. פתרון של למידת מכונה הוא זיהוי אנומליות – כלומר לפני חציית סף קשיח או כמה מהם.
אפשר לרתום את זה לשימושים יותר רציניים כמו אבחון של גפ״מ למשל, רטיבות או גזים אחרים. אבל איפה הכיף פה?
אנחנו צריכים לעשות את הדברים הבאים:
- לאסוף נתונים של ביקור סביר בשירותים. זה קל לעשות. הנתונים האלו נקראים Dataset ובעברית אני כותב דאטהסט. אפשר לייצר גם דאטהסט סינתטי. הכל נכנס לתוך csv.
- אחרי שאוספים או מייצרים את המידע, מעבירים אותו נורמליזציה ויוצרים ״חלונות״ של 50 מדידות שונות בדאטהסט שלנו. כל חלון כזה מוזן לתוך csv נוסף. אחר כך, הקלט של המודל יהיה 50 מדידות אמיתיות. את התוצאה של החלונות אנחנו שומרים ב-csv נוסף.
- בנייה ואימון המודל על ה-csv של החלונות. המודל הוא Autoencoder Model שהוא אולטרא פופולרי להרבה צרכים ואותנו הוא ישמש לאיתור אנומליות. הוא יקבל את המידע שהכנו קודם.
- המרה של המודל ל tflite ובדיקה בפייתון לראות שהכל תקין. את ה-tflite נוכל לדפלט ל-ESP32.
איסוף הדאטהסט או ייצור שלו
איסוף המידע הוא קל. בגדול, אני רוצה לאסוף את המידע כל X זמן, לצורך העניין כל שניה. איך אוספים מידע? ובכן, זה קל. מחברים חיישן גזים אל ESP32 ואוספים את המידע. יש לא מעט ��יישני גזים שאפשר לקנות בעליאקספרס בדולר וחצי. זה שאוסף מתאן נקרא MQ4. אנו יכולים לאסוף את המידע במיקרובקר ואז להוריד אותו או (עדיף) לשדר אותו באמצעות MQTT לשרת אחר. יכול להיות על המחשב שלנו או על רספברי פיי. אם כל המונחים האלו נשמעים כמו מדע בדיוני, אז אזכיר שוב כדאי מאד לגשת למאמר המבוא שלי ל-AIoT שיחבר אתכם לאן שצריך.
נצטייד ב-ESP32-WROOM ובחיישן MQ4. אם לא עבדתם עם חיישני גזים בעבר, שימו לב שאת רובם חייבים לחבר למתח של 5V (כלומר להשתמש ב-ESP32 שיש בו פין של 5V) ולתת להם זמן להתחמם. באלו שאני משתמש יש שני LEDS. אחד אדום, שמסמן על מתח והשני ירוק, שמראה על הכנה לפעולה. בלי הקפדה על שני הפרטים האלו הקריאות יהיו לא מדויקות בעליל. קחו בחשבון.
אם הכל עובד זה נהדר, אבל יש הבדל בין להדפיס לקונסולה לבין לאסוף את המידע. הדרך הכי טובה היא לשלוח את המידע לשרת אחר שיוכל לקחת אותו לשמור אותו. אפשר לשלוח עם MQTT או עם בקשת HTTP.
התחלתי לאסוף את המידע בסיוע של הילדים. אבל אז יעל, זוגתי, התערבה בסיפור ועצרה את הניסוי. גם לפעמים יש לנו בעיה של איסוף מידע ואנחנו צריכים להשתמש בדרך אחרת. איזו דרך? אפשר גם ליצור דאטהסט סינתטי. כלומר נתונים מזויפים זו דרך פחות טובה. אבל אם אין לכם כוח להתחיל להכנס לתוך שירותים או לבקש מהילדים לעבור ליד החיישן בכל פעם שבא להם לשחרר את הציפור או בת/בן זוגכם גם כך שניה מהגשת בקשת גירושין, אז לפעמים זו דרך טובה להתחיל לעבוד. את איסוף המידע האמיתי אפשר להמשיך ולטייב את המודל.
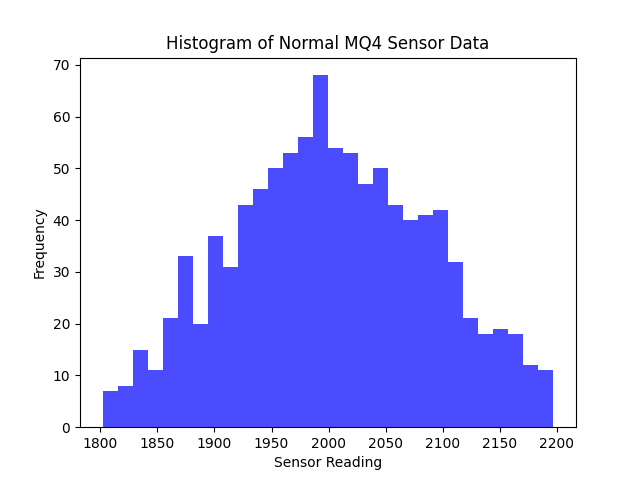
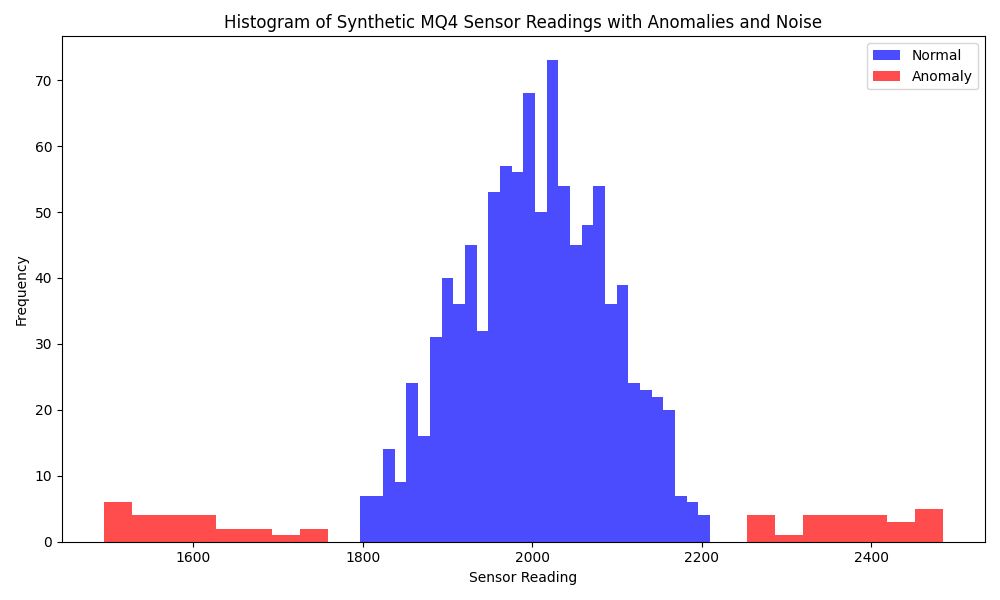
בואו וניצור דאטהסט סינתטי, שזה מילה יפה לדאטהסט מזויף. במקרה הזה עשיתי מדידות והחיישן שלי מוציא בערך בין 1800 (אוויר נקי) לבין 2200 (מתחיל להיות קצת מסריח) כאשר טירוף אמיתי מתחיל ב-3000. אבל כשזה יגיע, זה כבר לא מעניין אותי. אני אדע שיש מצב חירום כשהוא עובר את ה… 2700. אני רוצה לדעת שמשהו לא טוב מתבשל (הא!) כשהכל לכאורה תקין.
אז איך מארגן את זה? אמרנו טווח של 1800-2200 בהתפלגות נורמלית פחות או יותר. אז משהו שנראה ככה:
ועכשיו אני כן ארצה להוסיף outlies. כל מיני דגימות שמוסיפות רעש כדי שזה לא יהיה מסודר. כמו בחיים האמיתיים.
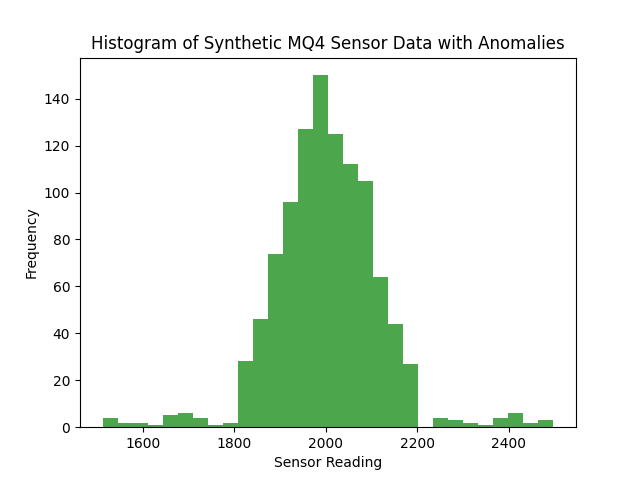
אם יש לי חריגות של יותר מ-2700 (או קיי, חריגה קיצונית) או פחות מ-1000 (החיישן התקלקל) – אז אני לא צריך בדיקת אנומליה, מספיק לי להוסיף בדיקת Threshold. העניין הוא, שוב, להתריע לפני שמשהו פה לא בסדר. או שהאוויר נקי מדי (מישהו אוגר) או שהוא מתחיל להיות בעייתי (מישהו מתחיל לשחרר טיפין-טיפין).
איך אני יוצר את הדאטהסט הזה? בימים של צ׳אט ג׳יפיטי, אפשר לבקש ממנו ליצור דאטהסט כזה, אבל כן להעביר לו את הפרמטרים של הערכים שאתם רוצים וההתפלגות המבוקשת. כאן אפשר כן להצמד למדידות בשטח. הוא יתן לכם את קוד הזה בפייתון. התקינו את המודולים panda, scipy ו-numpy אצלכם. עם פואטרי או uv.
שימו לב למשהו חשוב – חייבים להכניס קצת רעש ולבצע שינויים בהגדרת מה לא נורמלי. למה? כי ללא רעש, המדידות יהיו צפויות. אני מצרף צילום מסך של חמש חלונות שעשיתי על הדאטהסט הסינתטי ללא הוספת רעש וללא שינוי הגדרה של לא נורמליות. נסו להסתכל עליהם ולהבין מה הבעיה (רק העליון מסווג כנורמלי):
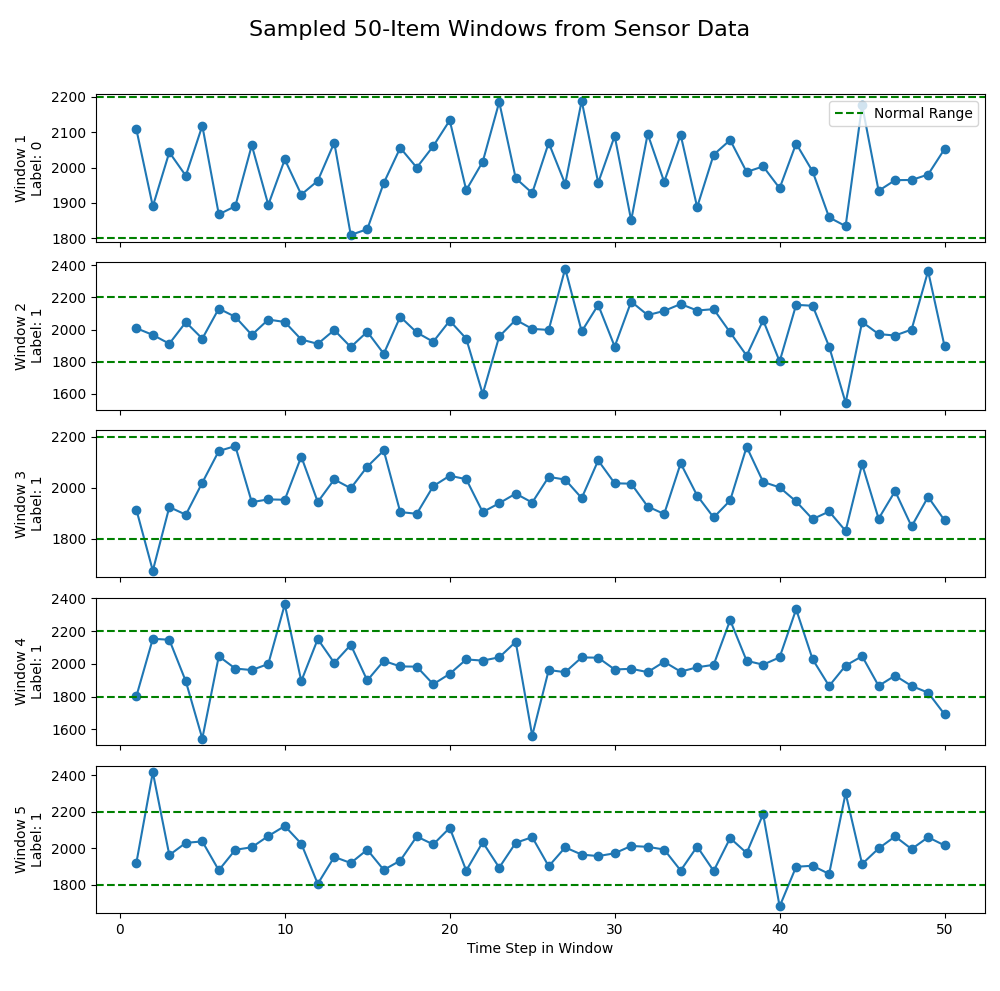
מה הבעיה?
כל מה שהוא מתחת ל-1800 ומעל ל-2200 נחשב לא נורמלי וכל חריגה מתוארת כמשהו לא נורמלי. טוב, כי המידע שלנו הוא סינתטי. אם נאמן את המודל הוא פשוט ילמד את זה ואז נחזור לבעיית ה-Threshold. אנחנו חייבים להכניס קצת רעש. פה שוב, או שנכניס ידנית ל-dataframe, או שנציק לבינה המלאכותית שמייצרת את הקוד של הדאטהסט שתוסיף רעש וגם שלא תגדיר כל חריגה קטנה מהטווח כאנומליה. שיראה קצת יותר אמיתי. ככה:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import truncnorm
# ------------------------------
# 1. Generate the "Normal" Sensor Data
# ------------------------------
# Parameters for the sensor readout
mean = 2000
std = 100
lower_bound = 1800
upper_bound = 2200
# Convert bounds for truncnorm (standardized values)
a, b = (lower_bound - mean) / std, (upper_bound - mean) / std
# Number of normal samples to generate
n_normal = 1000
# Generate normal data using the truncated normal distribution
normal_data = truncnorm.rvs(a, b, loc=mean, scale=std, size=n_normal)
# ------------------------------
# 2. Inject Anomalies into the Data
# ------------------------------
# Define the fraction of anomalies (e.g., 5% of the normal data)
anomaly_fraction = 0.05
n_anomalies = int(n_normal * anomaly_fraction)
# Generate anomalies:
# Half of the anomalies are unusually low, and half are unusually high.
anomaly_low = np.random.uniform(1500, 1750, size=n_anomalies // 2)
anomaly_high = np.random.uniform(2250, 2500, size=n_anomalies - n_anomalies // 2)
# Combine the anomalies
anomalies = np.concatenate([anomaly_low, anomaly_high])
# Merge the normal data with the anomalies
synthetic_data = np.concatenate([normal_data, anomalies])
# Shuffle the combined data so that anomalies are not clustered
np.random.shuffle(synthetic_data)
# ------------------------------
# 3. Add Noise to the Sensor Readings
# ------------------------------
# Define the noise standard deviation (adjust as needed)
noise_std = 10
# Add Gaussian noise to all sensor readings
noisy_data = synthetic_data + np.random.normal(0, noise_std, size=synthetic_data.shape)
# ------------------------------
# 4. Create a DataFrame and Classify Anomalies with Tolerance
# ------------------------------
# Create a DataFrame with a column for the noisy sensor readings
df = pd.DataFrame({'sensor_reading': noisy_data})
# Define a tolerance margin to avoid flagging small noise-induced deviations.
# For example, we allow a margin of 30 around the original normal bounds.
tolerance = 30
adjusted_lower = lower_bound - tolerance # e.g., 1800 - 30 = 1770
adjusted_upper = upper_bound + tolerance # e.g., 2200 + 30 = 2230
# Flag an anomaly only if the reading is well outside the adjusted range.
df['is_anomaly'] = ((df['sensor_reading'] < adjusted_lower) |
(df['sensor_reading'] > adjusted_upper)).astype(int)
# ------------------------------
# 5. Save the Data to a CSV File (Optional)
# ------------------------------
csv_filename = "synthetic_mq4_data.csv"
df.to_csv(csv_filename, index=False)
print(f"Data has been saved to {csv_filename}")
אפשר לטעון את מסד הנתונים הנפלא הזה בפנדה ולבחון אותו יותר לעומק או להעשיר אותו לפי מדידות אמיתיות שעשיתם.
הכנת הדאטהסט שלנו לאימון
השלב הבא הוא להכין את הדאטהסט לאימון, אנחנו נגזור בכל פעם חמישים מדידות ונראה אם הן נורמליות או לא נורמליות (אנומליות). אנחנו נשתמש בדאטהסט הסינתטי שהכנו ושמרנו ב-"synthetic_mq4_data.csv", נסמן כל קריאה כ"אנומלית" אם היא מחוץ לטווח 1800–2200, ואז מחלק את הנתונים לחלונות חופפים של 50 קריאות. עבור כל חלון תהיה ספירה את מספר הקריאות האנומליות והחלון כ"אנומלי" רק אם לפחות 5 מתוך 50 ��קריאות הן מחוץ לטווח. לבסוף, הקוד ניצור קובץ CSV חדש בשם "prepared_mq4_training_data.csv" שיכיל את חלונות הנתונים עם התוויות (אנומלי ונורמלי). התוויות הן בשבילנו, אגב, אנחנו לא משתמשים בהן בתהליך האימון. הן מאפשרות לי לבחון את המידע שלי. למשל עם גרפים נחמדים כאלו:
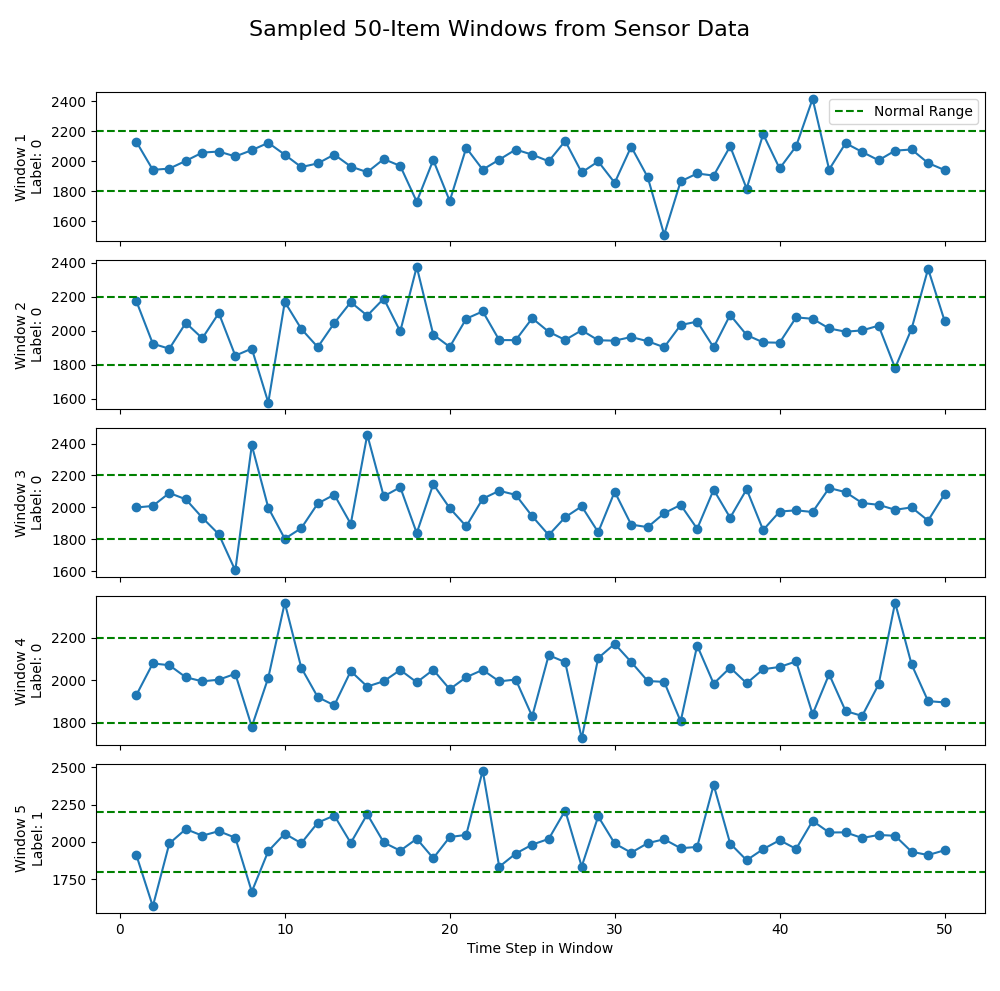
שימו לב לשינוי בין מה שהיה עם הדאטהסט ללא הרעש לבין לבין מה שיש עכשיו – זה שמוגדר כחלון זמן נורמלי כבר לא מכיל אפס קריאות שלא בנורמה אלא התמונה מורכבת יותר.
import pandas as pd
def create_windows(data, window_size=50):
"""
Create sliding windows from the data.
Each window contains 'window_size' consecutive readings.
"""
windows = []
for i in range(len(data) - window_size + 1):
window = data[i:i + window_size]
windows.append(window)
return windows
if __name__ == "__main__":
# Load the synthetic data
df = pd.read_csv("synthetic_mq4_data.csv")
readings = df["sensor_reading"].values
# Create windows of 50 readings
windows = create_windows(readings, window_size=50)
# Create a DataFrame with column names reading_1 to reading_50
columns = [f"reading_{i + 1}" for i in range(50)]
df_windows = pd.DataFrame(windows, columns=columns)
# Save the prepared training data
df_windows.to_csv("prepared_mq4_training_data.csv", index=False)
print("Prepared training data saved to prepared_mq4_training_data.csv")
עכשיו, כשיש לנו מידע מוכן לאימון, כלומר סדרה של חלונות חופפים של מדידות שחלקן מזוהות כנורמליות וחלקן כאנומליות, נתחיל ליצור מודל.
אימון המודל (ומה זה אומר בכלל)
האימון משמעותו ליצור פונקציה שבה המודל "לומד" גבול החלטה שמפריד בין דפוסים תקינים לבין דפוסים חריגים, ולא מחבר באופן ישיר בין אנומליות. יש באמת המון שיטות לאימון מודלים וזה באמת עולם ומלואו ואני לא מגזים, אבל חשוב רק להבין בערך מה המטרה – ליצור מודל שמנסה לחזות מידע עתידי לפי הסתברות. המודל יקבל 50 מדידות ואז יחזיר לנו מה הסיכוי שיש אנומליה. זו המטרה של האימון, לתת לו את כל המידע שיש לנו כדי שידע להחזיר לנו סיכוי.
יש המון מודלים כאלו שאפשר להשתמש בהם כדי לזהות אנומליות. אנחנו נשתמש ב-Autoencoder – גם פה אני לא רוצה וגם לא יכול לבצע חפירה על השינויים בין המודלים האלו. מדובר במודל פשוט להבנה, זול ליישום ושקל לעבוד איתו. האימון של Autoencoder מתבסס על שחזור קלט. אפשר להשתמש בו לזיהוי אובייקטים ולמגוון משימות בלמידת מכונה – אנחנו נשתמש בו כדי למדוד אנומליות וזה מה שחשוב לזכור – המודל לומד כיצד לייצג בצורה מתמטית את הדפוסים הרגילים, וכך לזהות סטיות מהתבנית הזו. זהו.
אפשר לומר בהכללה ג��ולה שאימון מודל של Autoencoder זה להגדיר פונקציה (באמצעים שונים – למשל באמצעות טכניקה שנקראת רשת נוירונים). היא בעצם דוחסת את המידע שהעברנו לה ואז מנסה לבנות אותו מחדש עם הפונקציה הזו. אם יש הבדל בין הבניה מחדש למידע האמיתי – יש לנו אנומליה.
הקלט של הפונקציה הוא חלון הנתונים האמיתי. הפלט הוא חלון הנתונים שהיא בונה מחדש על פי הפונקציה שיש לה. ההבדל בינהם הוא ההסתברות שהחלון הוא אנומלי או לא.
כאמור אפשר להשתמש ב-ChatGPT כדי לייצר את הקוד שמאמן את המודל. חשוב רק להבין מה לעשות ולהנחות את ChatGPT. לציין בפניו את המודל שאתם רוצים, את גודל החלון, אפילו להזין לו חלק מהדאטהסט. עוד משהו שצריך לומר לו זה שיבצע נורמליזציה. הנה הקוד שלי:
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers, models
def load_data(filename):
"""
Load the training data from CSV.
"""
df = pd.read_csv(filename)
return df.values
def build_autoencoder(input_dim):
"""
Build a simple autoencoder model.
The encoder compresses the 50-dimensional input to a lower-dimensional representation,
and the decoder reconstructs the input.
"""
input_layer = tf.keras.Input(shape=(input_dim,))
# Encoder
encoded = layers.Dense(25, activation='relu')(input_layer)
encoded = layers.Dense(12, activation='relu')(encoded)
# Decoder
decoded = layers.Dense(25, activation='relu')(encoded)
decoded = layers.Dense(input_dim, activation='linear')(decoded)
autoencoder = tf.keras.Model(inputs=input_layer, outputs=decoded)
autoencoder.compile(optimizer='adam', loss='mse')
return autoencoder
if __name__ == "__main__":
# Load training data
data = load_data("prepared_mq4_training_data.csv")
input_dim = data.shape[1] # Should be 50
# Build and train the autoencoder
autoencoder = build_autoencoder(input_dim)
autoencoder.fit(data, data, epochs=50, batch_size=32, validation_split=0.1)
# Convert the trained model to TensorFlow Lite
converter = tf.lite.TFLiteConverter.from_keras_model(autoencoder)
tflite_model = converter.convert()
# Save the TFLite model
with open("mq4_anomaly_detection_model.tflite", "wb") as f:
f.write(tflite_model)
print("TensorFlow Lite model saved to mq4_anomaly_detection_model.tflite")
צרות ובעיות בהרצה ובהתקנה לבעלי מק אינטל
אם יש לכם מק מסדרת M או חלונות שד׳ ישמור ויציל, דלגו הלאה. אם יש לכם מק אינטל – יש סיכוי שיהיו לכם בעיות בהתקנה. על מנת לאמן, תצטרכו להתקין tensorflow. שימו לב שזה עלול להיות בעייתי כי לפעמים יש התנגשויות של תלויות – במיוחד עם numpy וכדי להגדיל את השמחה – אם יש לכם מק אינטל אז לא תוכלו להתקין את הגרסה הכי חדשה. למרות שב-pypi יש גרסאות יותר חדשות, ה-wheel של tensorflow לא קיים למק אינטל בגרסאות האלו.
במקרה של מק אינטל – הגרסה שאפשר להתקין מהניסיון שלי היא 2.2.0 והיא באה עם numpy גרסת 1.9. שימו לב פשוט כשאתם מתקינים את זה על המק שלכם לא להתבאס מזה או לשבור את הראש אלא ישר לשנמך את Tensorflow אם יש כשלון בהתקנה.
כמה דברים שצריך לזכור בנוגע לגילוי אנומליות
צריך לקחת את כל מה שאני כותב כאן עם קורטוב מלח כי העולם הזה של בדיקת אנומליות הוא ה-ר-ב-ה יותר מורכב. כלומר בשביל חיישן לבית או לימוד ראשוני של זיהוי אנומליה זה בסדר גמור. אבל סביבת פרודקשן זה סיפור אחר. למשל, צריך לקחת בחשבון. שהמודל מתבסס על הדאטהסט שבו אומן, ולכן אם הדאטהסט אינו מייצג היטב את כל המצבים האפשריים, ייתכן שיתקבלו False Positives (זיהוי שגוי של אנומליות) או False Negatives (פספוס של אנומליות אמיתיות). בעיה נוספת היא רגישות לרעש. מכיוון שהמודל לומד דפוסים מהמידע המציאותי או מדאטהסט סינתטי, הוא עשוי להיות מושפע משינוי של הקריאות, גם אם הן אינן בהכרח מעידות על אנומליה. זה יכול לגרום לו לסמן אנומליות על סמך דברים טבעיים (למשל מיקום החיישן בשירותים) במקום על אירועים משמעותיים. פתרון אפשרי לכך הוא נורמליזציה קפדנית של הנתונים, הגדרת טווחי סף מותאמים ושימוש בכמה שיותר מידע אמיתי. צריך לזכור ש Autoencoders פועלים מעולה כאשר הם מזהים דפוסים מוכרים אך הוא יותר בעייתי כאשר אין כאלו.
גם יש שיטות רבות נוספות לגילוי אנומליות ולא תמיד רשת נוירונים היא השיטה הכי טובה – לפעמים אפשר לעשות עיבוד סטטיסטי אחר, אבל אני לא נכנס לדקויות אלו במאמר זה שגם כך הולך ומתנפח.
בדיקה
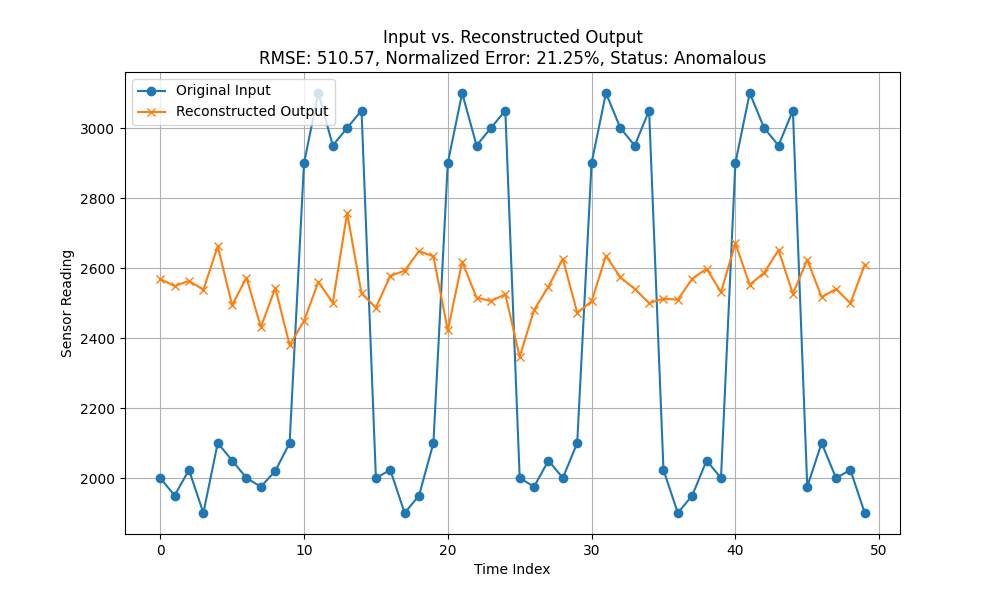
עכשיו כשיש לנו מודל, אפשר לבדוק אותו. יש כמובן דרכים מקצועיות לבדיקה והערכה של מודלים, לא נדון בהן כאן. המאמר הזה בסופו של דבר הוא על חיישן גזים – אז הבדיקה שלנו תהיה יותר אינטואיטיבית ואת ענייני ההערכה של המודל נשמור לפוסט אחר. כדי לראות שבכלל המודל עובד ולא מוציא שטויות, נעשה קצת בדיקת Sanity. ניצור (או ניקח מהמדידות שלנו) סדרה של 50 תצפיות שבמבחינתנו היא אנומלית. יכול להיות שזה בדיוק מה שמדדנו לפני הסרחה רצינית. לי יש למשל מדידה שלקחתי לפני שאחד הילדים שלי עשה ״הירושמה 2: הנקמה״ בחדר. בגדול בעין המדידה היא אנומלית. בגרף הזה ממש רואים את מה שהמודל חזה (ה-reconstructed) לעומת המדידה האמיתית שהיא באמת אנורמלית. בקו הכחול רואים את ההפרחות השקטות שלא חצו את ה-Threshold (ואז עצירה) לעומת משהו שסביר להניח שהמודל חזה.
import numpy as np
import tensorflow as tf
def load_tflite_model(model_path):
"""
Load and initialize the TensorFlow Lite model.
"""
interpreter = tf.lite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
return interpreter
def run_inference(interpreter, input_data):
"""
Run inference using the TFLite model.
"""
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
return output_data
def compute_normality(input_data, reconstructed, threshold=1.0):
"""
Compute the Root Mean Squared Error (RMSE) between the input and reconstructed output.
Then normalize this error as a percentage of the mean of the input.
If the normalized error is below the threshold (in percent), we label it as "Normal";
otherwise, we label it as "Anomalous."
Parameters:
input_data: The original input array.
reconstructed: The model's reconstructed output.
threshold: Normalized error percentage threshold.
Returns:
rmse: The root mean squared error.
normalized_error: The RMSE expressed as a percentage of the mean input value.
status: "Normal" or "Anomalous" based on the threshold.
"""
rmse = np.sqrt(np.mean((input_data - reconstructed) ** 2))
normalized_error = rmse / np.mean(input_data) * 100
status = "Normal" if normalized_error < threshold else "Anomalous"
return rmse, normalized_error, status
if __name__ == "__main__":
custom_tuple = (
2000, 1950, 2023, 1900, 2100, 2050, 2000, 1975, 2020, 2100,
2900, 3100, 2950, 3000, 3050,
2000, 2023, 1900, 1950, 2100,
2900, 3100, 2950, 3000, 3050,
2000, 1975, 2050, 2000, 2100,
2900, 3100, 3000, 2950, 3050,
2023, 1900, 1950, 2050, 2000,
2900, 3100, 3000, 2950, 3050,
1975, 2100, 2000, 2023, 1900
)
# Convert the tuple to a numpy array with shape (1, 50)
test_input = np.array(custom_tuple, dtype=np.float32).reshape(1, -1)
# Load the TFLite model
interpreter = load_tflite_model("mq4_anomaly_detection_model.tflite")
# Run inference on the custom tuple
reconstructed = run_inference(interpreter, test_input)
# Compute RMSE and normalized error (set threshold appropriately based on your calibration)
rmse, normalized_error, status = compute_normality(test_input, reconstructed, threshold=3.0)
print("Custom Test Input:")
print(test_input)
print("\nReconstructed Output:")
print(reconstructed)
print("\nRMSE: {:.2f}".format(rmse))
print("Normalized Error: {:.2f}%".format(normalized_error))
print("Status: {}".format(status))
פה יש לנו סף: הסף הוא אחוזים – בכמה אחוזים יש שוני בין הבנייה מחדש של סדרת הנתונים לסדרת הנתונים בפועל. כלומר מה שקורה הוא שהמודלר לוקח את הנתונים שהעברתי לו, מפרק את הנתונים ובונה אותם מחדש. אני מחשב את הדמיון בין הבנייה מחדש לבין המקור. אחוז נמוך אומר שאין הבדל משמעותי ביום הבנייה מחדש למקור – כלומר אין אנומליה. כשהאחוז גבוה יש הבדל יותר משמעותי. אני זה שקובע את ה-threshold הוא באחוזים וככל שהוא יותר נמוך כך אנחנו רוצים יותר התאמה לבנייה מחדש. וכך אני מכוון את הרגישות של המודל.
נבדוק את זה מול משהו מעט יותר נורמלי – למשל קריאה אמיתית מהבית:
custom_tuple = (
2000, 2050, 2023, 1900, 2100,
2050, 2000, 1975, 2020, 2100,
2023, 2100, 2023, 2045, 1950,
2000, 2023, 1900, 1950, 2100,
1901, 2100, 2050, 2043, 1974,
2000, 1975, 2050, 2000, 2100,
2086, 2104, 2078, 2050, 2050,
2023, 1900, 1950, 2050, 2000,
2045, 1987, 1968, 1914, 1900,
1975, 2100, 2000, 2023, 1900
)אני אראה שלמרות שיש שינוי בין הבניה מחדש לתוצאות האמת – השינוי בין התוצאות הוא פחות משלושה אחוזים (תנאי הסף שבחרתי) ולפיכך היא נורמלית.
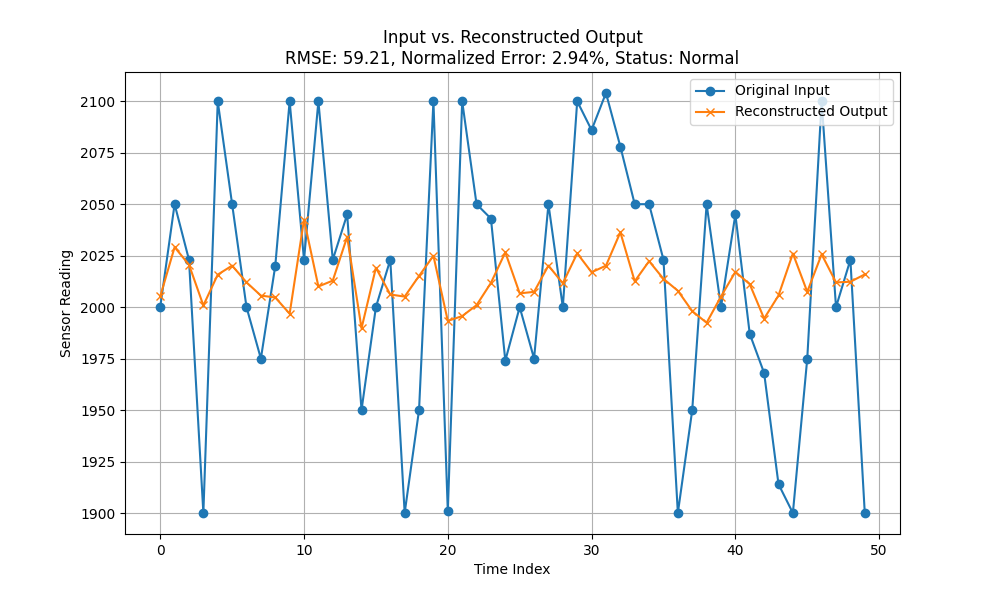
זה השלב שבו אפשר לשנות לא מעט את המודל בהתאם לתוצאות של העולם האמיתי. יש יותר מידע? נאמן את המודל מחדש. יוצא לנו שמידע נורמלי לגמרי מביא לאבחון שגוי? נשנה את חישוב השוני בין הניבוי ללא ניבוי או ננרמל את התוצאות. יש המון דברים שאפשר לעשות ולנתח. אבל בסופו של יום – יש לנו מודל ודרך לחשב את האנומליה. יש לנו tflite וקוד, אנחנו יכולים לדחוף את הקוד הזה לתוך מיקרו בקר מסוג ESP32 כדי שיוכל לבצע הערכה (והרחה! חה!) בזמן אמת ואז לתת סירנה כשיש לנו אנומליה עוד לפני שיש התפרצות. לזה קוראים מדע!